Spring WebClient连接池泄漏问题分析
最近在一个http代理项目中使用了Spring的Webclient实现http请求的异步处理,其采用的响应式编程模型reactive programming可以减少资源消耗提高系统吞吐量,并以一种更具可读性的方式实现整个数据处理的异步化。
项目上线后如期稳定运行,直到一次机房网络故障导致某个业务系统压力过大,http请求持续报错。我想既然业务后端有问题,这边客户端请求报错也是理所当然,只要有降级策略不影响其他业务请求也就无关大碍,所以一开始也没当回事。直到发现业务系统恢复之后,http请求报错仍然继续,才发现肯定是有bug了。事实证明,想当然是不可靠的。
在问题发生之后,我也一头雾水,不清楚是何原因导致请求没有恢复正常,无奈只能先重启项目实例,结果发现新的请求神奇的恢复正常了(重启解决一切:))。毕竟是线上服务,需要尽快找出问题的原因及解决方案,所以就有了接下来漫长的bug分析之路。
现象
首先是查看线上服务器关键时间点的日志。
第一,是业务后端恢复之后的错误日志,所有新进来的请求都在报PoolAcquireTimeoutException异常,异常栈如下:
e:reactor.netty.internal.shaded.reactor.pool.PoolAcquireTimeoutException:
Pool#acquire(Duration) has been pending for more than the configured timeout of 45000ms
at reactor.netty.internal.shaded.reactor.pool.AbstractPool$Borrower.run(AbstractPool.java:317)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:68)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:28)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
...
这个异常官方文档解释如下:
A specialized TimeoutException that denotes that a Pool.acquire(Duration) has timed out. Said Duration can be obtained via getAcquireTimeout().
意思是从连接池Pool中获取连接超时,这边默认超时时间是45000ms,和日志中一致,看起来是没有获取到可用连接,和连接池有关系(连接池一看就不是善茬…)。
第二,是业务后端出现故障的时间点上下文的错误日志中,有如下错误:
ReadTimeoutException意思是读取超时,表示从服务端获取响应超过了设定的时间。这个错误说明服务端压力过大或者网络异常,来不及响应。
WARN [reactor-http-epoll-92] r.n.h.c.HttpClientConnect -
[id: 0xae4ffbc3, L:/localhost:54344 - R:xxxxxx/xxxxxx:80] The connection observed an error
io.netty.handler.timeout.ReadTimeoutException: null
ConnectTimeoutException意思是连接超时,表示建立TCP连接超过了设定的时间,这个错误也说明服务端压力过大或者网络异常,来不及响应
e:io.netty.channel.ConnectTimeoutException:
connection timed out: L:/localhost:54344 - R:xxxxxx/xxxxxx:80
at io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe$2.run(AbstractEpollChannel.java:570)
at io.netty.util.concurrent.PromiseTask$RunnableAdapter.call(PromiseTask.java:38)
at io.netty.util.concurrent.ScheduledFutureTask.run(ScheduledFutureTask.java:127)
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:163)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:416)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:331)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:918)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:745)
PrematureCloseException意思是连接被永久关闭,具体错误信息表示在等待数据响应的时候连接被关闭。这个错误是在服务器响应阶段造成的,可能是服务端压力过大异常关闭了连接。
WARN [][reactor-http-epoll-66] r.n.h.c.HttpClientConnect -
[id: 0xae4ffbc3, L:/localhost:54344 - R:xxxxxx/xxxxxx:80] The connection observed an error
reactor.netty.http.client.PrematureCloseException: Connection prematurely closed BEFORE response
业务后端出现故障的时间点的错误日志均说明服务端当时压力过大,但是为什么服务端恢复之后,客户端仍然在报PoolAcquireTimeoutException的原因不得而知。
接下来介绍下项目中所用的Spring的WebClient。WebClient本身并没有实现http请求的相关逻辑,其底层是采用的是reactor-netty的http客户端(也是这次问题的始作俑者),WebClient只是对其做了一个封装。reactor-netty是基于netty并结合reactor模型实现的tcp/udp/http异步库。线上运行的reactor-netty的版本如下:
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty</artifactId>
<version>0.9.1.RELEASE</version>
</dependency>
最后是项目的运行环境:
- jvm
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
- os
Linux 3.10.0-693.21.1.el7.x86_64 #1 SMP Wed Mar 7 19:03:37 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
分析
github issue
既然是开源项目,第一时间就是上github看看有没有相关issue,可能早就有人提过并解决,这样升级一下版本就能把这个恼人的bug给解决掉。
幸运的是的确有人提过相关的issue:
-
第一个issue是关于
0.9.1.RELEASE版本,也是我项目中使用的版本,提出连接异常关闭的情况下连接没有被释放,但作者已经在0.9.2.RELEASE中修复了此问题,具体的修改是在连接关闭的时候添加hook机制进行连接的释放。 -
第二个issue是关于
0.9.5.RELEASE版本,这个issue中提到连接仍然存在泄漏。具体的说,每当客户端在等待数据响应过程中连接被中断的话,这个连接还是会被占用,并没有归还到连接池中,最终会导致整个连接池处于不可用的状态,表现就是连接池泄漏了,从而新来的请求都不会被处理并且抛出获取连接超时的异常。
这两个issue描述的现象和我们上面的错误日志非常吻合,故障发生点的时刻上下文中的确出现了批量的PrematureCloseException异常,而且系统最终的表现也是新来的请求都抛出PoolAcquireTimeoutException异常。
为了验证第二个issue中的问题仍然存在,尝试升级项目中的reactor-netty至最新版本。按照issue中的说法,是客户端在读取响应阶段,后端连接突然断开导致的。那么只要在大量请求的情况下,直接杀掉后端进程即可达到这种效果。测试环境重复几次之后,还是复现了生产环境中的现象,连接池被耗尽,新来的请求抛出获取连接超时异常。
不幸的是第二个issue提出的版本是当时最新的版本,连接泄漏的问题并没有被解决掉,通过升级版本解决问题的美梦破碎。
但这个问题造成的负面影响还是很严重的,只要后端业务系统不稳定,客户端就会出现连接泄漏的问题,而且还不会自动恢复(可怕…)。毕竟是线上运行的系统,看来必须要研究下其开源实现,看看有没有什么解决方案。
连接池
连接池,顾名思义,就是复用连接。这里的连接是指底层的TCP连接,对系统而言是一个重资源,如果频繁断开重连,会对系统性能造成很大的损失,和线程池一个道理。对于HTTP请求,支持在header中设置keep-alive来告诉服务器复用连接,而不用每次请求都进行tcp的三次握手。
reactor-netty中也实现了http连接池,其支持弹性(elastic)的和固定(fix)的连接池。弹性连接池的连接数是无界的,而固定连接池的连接数是有界的。显然,无界连接池在不受限制的情况下会造成OOM的问题,所以reactor-netty默认使用的固定连接池,连接池的默认上限为500。
如果是连接池的问题,那么是什么原因导致新的请求获取不到连接从而超时的呢?
日志分析
我们可以在测试环境中开启DEBUG日志,先分析下reactor-netty中一次正常的http请求过程,是如何进行连接的获取、完成http请求、归还连接的。可以在日志中grep连接channel的id来筛选出与连接有关的日志帮助分析。
- 一次正常的http请求的完整的debug日志如下所示:
连接获取阶段,从连接池中获取一个连接
2020-02-27 15:53:35,518 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
Channel acquired, now 481 active connections and 19 inactive connections
请求准备阶段,准备http请求
2020-02-27 15:53:35,518 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [request_prepared])
请求发送阶段,发送http请求
2020-02-27 15:53:35,536 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [request_sent])
响应接收阶段,开始接收http响应
2020-02-27 15:53:35,835 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [response_received])
响应接收阶段,接收完http响应
2020-02-27 15:53:35,835 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [response_completed])
http请求结束
2020-02-27 15:53:35,835 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [disconnecting])
开始连接释放
2020-02-27 15:53:35,835 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
Releasing channel
完成连接释放
2020-02-27 15:53:35,835 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
Channel cleaned, now 495 active connections and 5 inactive connections
从上面日志可以看出,如果采用连接池的话,一个完整的成功的http请求会经历如下阶段:

大致流程就是从连接池中获取(acquire)一个tcp连接,然后进行完整的http请求响应,最后将连接释放(release)到连接池中供后续请求使用。注意到连接释放的日志中显示了连接池中活跃连接(active connection)和不活跃连接(inactive connection)的数目。这里active是指连接目前已被请求占用,而不是指连接是否正常。
- 而造成连接泄漏的http请求日志如下所示:
连接获取阶段,从连接池中获取一个连接
2020-02-27 15:53:36,701 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
Channel acquired, now 495 active connections and 0 inactive connections
请求准备阶段,准备http请求
2020-02-27 15:53:36,701 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [request_prepared])
请求发送阶段,发送http请求
2020-02-27 15:53:36,712 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 - R:10.39.10.28/10.39.10.28:8080]}}, [request_sent])
连接异常关闭
2020-02-27 15:53:36,842 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 ! R:10.39.10.28/10.39.10.28:8080]
Channel closed, now 498 active connections and 0 inactive connections
http响应未完成
2020-02-27 15:53:36,858 DEBUG [][reactor-http-epoll-5] r.n.r.PooledConnectionProvider -
[id: 0x6305c6cf, L:/172.17.0.6:36764 ! R:10.39.10.28/10.39.10.28:8080]
onStateChange(GET{uri=/metrics/ping, connection=PooledConnection{
channel=[id: 0x6305c6cf, L:/172.17.0.6:36764 ! R:10.39.10.28/10.39.10.28:8080]}}, [response_incomplete])
报错,连接在接收响应前永久关闭
2020-02-27 15:53:36,858 WARN [][reactor-http-epoll-5] r.n.h.c.HttpClientConnect -
[id: 0x6305c6cf, L:/172.17.0.6:36764 ! R:10.39.10.28/10.39.10.28:8080]
The connection observed an error
reactor.netty.http.client.PrematureCloseException: Connection prematurely closed BEFORE response
从上面日志可以看出由于连接异常关闭导致http响应未完成,然后抛出PrematureCloseException错误,跳过了连接释放阶段,没有归还连接。
上面连接关闭的日志显示还有498个活跃连接,但其实在机器上执行ss命令查看已经没有tcp连接了。似乎是找到了rootCause, 但真实的情况是这样吗?
代码分析
issue中的开源库作者提到,代码中有注册hook机制,每当channel被关闭时,hook会进行连接的释放操作,操作完成后会打印Channel closed的日志,这个效果和Channel cleaned是一样的。可以看下这段hook代码:
void registerClose(PooledRef<PooledConnection> pooledRef, InstrumentedPool<PooledConnection> pool) {
Channel channel = pooledRef.poolable().channel;
if (log.isDebugEnabled()) {
log.debug(format(channel, "Registering pool release on close event for channel"));
}
channel.closeFuture()
.addListener(ff ->
pooledRef.invalidate()
.subscribe(null, null, () -> {
if (log.isDebugEnabled()) {
log.debug(format(channel, "Channel closed, now {} active connections and " +
"{} inactive connections"),
pool.metrics().acquiredSize(),
pool.metrics().idleSize());
}
}));
}
这里的channel是netty中表示的一个tcp的连接,可以在其关闭用的ChannelFuture中注册回调函数。pooledRef.invalidate()其实就是进行执行真正的连接释放操作。
那刚才的解释就自相矛盾了,如果连接关闭,就会执行连接释放操作的话,那为什么还会有连接泄漏的问题存在呢。让我们进一步深入到连接池的具体实现来定位这个bug!
reactor-netty的连接池实现概略图如下所示:
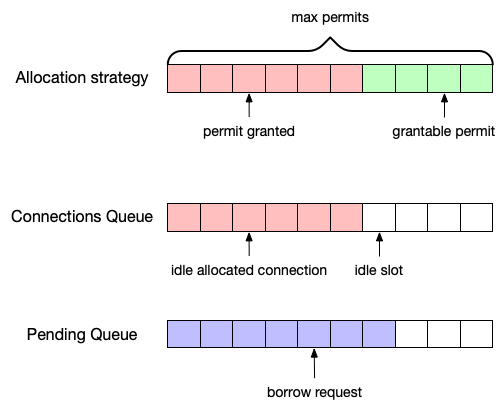
reactor-netty的连接池主要包括三大结构,分别是Pending Queue(等待队列)、Connections Queue(空闲连接队列)、Allocation Strategy(分配策略)。
-
Pending Queue(等待队列),主要是存放需要借用连接的新请求,可以称之为borrow request,请求被放入队列的时候就会开启一个定时器,当超过设置的超时时间时就会抛出本文一开始观察到的
PoolAcquireTimeoutException,表示连接一直没有借到。 -
Connections Queue(空闲连接队列),主要是存放空闲的连接。如果这个队列为空,说明目前没有空闲的连接,但不一定是没有可用连接,因为可能连接还没有创建。释放的空闲连接的会追加到队列之中,获取连接的时候会首先从队列中获取。它是一个无界队列,元素个数取决于接下来要讲到的分配策略。如果获取连接的时候这个队列为空,而分配策略又允许创建新的连接,那么就会创建新的连接供请求使用。需要说明的是,队列中存放的不是原始的连接对象,而是封装了真实连接的
PooledRef对象,代理了进行连接的释放等操作。 -
Allocation Strategy(分配策略),规定了最大可创建的连接数,其中每一个permit表示可以新建一个连接。每次新创建一个连接,就会消耗一个permit。相对应地,如果归还一个连接,会新增一个permit。
了解完reactor-netty连接池的大致原理后,我们再看下代码级别的连接获取和释放过程,连接获取的关键函数是下面的drainLoop函数:
for (;;) {
// 空闲连接数
int availableCount = elements.size();
// 等待的请求数目
int pendingCount = PENDING_COUNT.get(this);
// 允许新建立连接的permit数目,返回0则说明不能再新建连接
int estimatedPermitCount = poolConfig.allocationStrategy().estimatePermitCount();
if (availableCount == 0) {
// 如果既没有可用空闲连接,又没有可用permit, 则条件不满足循环重试
if (pendingCount > 0 && estimatedPermitCount > 0) {
final Borrower<POOLABLE> borrower = pendingPoll(); //shouldn't be null
if (borrower == null) {
continue;
}
ACQUIRED.incrementAndGet(this);
int permits = poolConfig.allocationStrategy().getPermits(1);
if (borrower.get() || permits == 0) {
ACQUIRED.decrementAndGet(this);
continue;
}
...
// 创建新连接
Mono<POOLABLE> allocator = poolConfig.allocator();
...
}
}
else if (pendingCount > 0) {
QueuePooledRef<POOLABLE> slot = elements.poll();
// 拿不到空闲连接,循环重试
if (slot == null) continue;
//拿到的连接是无效连接(已断开),则清理死连接
if (poolConfig.evictionPredicate().test(slot.poolable, slot)) {
destroyPoolable(slot).subscribe(null, e -> drain(), this::drain);
continue;
}
...
}
...
}
通过上述代码可以看出,Allocation Strategy中的permit控制着真实的连接数目。
连接释放过程是通过刚才提到的PoolRef对象,主要有两个方法,一个是release方法,连接正常释放的时候会调用,另一个是invalidate方法,在连接断开的时候通过hook回调使用。
首先看下poolRef.release()方法:
public Mono<Void> release() {
return Mono.defer(() -> {
// 已经释放过的不必再释放
if (STATE.get(this) == STATE_RELEASED) {
return Mono.empty();
}
...
return new QueuePoolRecyclerMono<>(cleaner, this);
});
}
// release会最终调用以下方法
final void maybeRecycleAndDrain(QueuePooledRef<POOLABLE> poolSlot) {
if (!isDisposed()) {
if (!poolConfig.evictionPredicate().test(poolSlot.poolable, poolSlot)) {
metricsRecorder.recordRecycled();
// 连接正常状态时,可以直接回收,这里会new一个新的PoolRef实例加入到Connections Pool中
elements.offer(recycleSlot(poolSlot));
drain();
}
else {
// 如果连接已经断开,则进行连接清理操作
destroyPoolable(poolSlot).subscribe(null, e -> drain(), this::drain);
}
}
else {
destroyPoolable(poolSlot).subscribe(null, e -> drain(), this::drain);
}
// 连接清理
Mono<Void> destroyPoolable(AbstractPooledRef<POOLABLE> ref) {
POOLABLE poolable = ref.poolable();
// 关键的调用,将permit归还,从而允许创建新连接
poolConfig.allocationStrategy().returnPermits(1);
...
}
从poolRef.release()的实现中,我们可以知道每一个PoolRef实例会维护一个STATE状态,有3种状态:
-
STATE_IDLE(0), 空闲状态,也是实例构造时的初始状态 -
STATE_ACQUIRED(1), 获取状态,表示目前连接被占用 -
STATE_RELEASED(2), 释放状态,表示目前连接已被释放
需要注意的是,如果连接正常并进行连接回收的时候,是新构造一个PoolRef实例并放入Connections Queue中,而是不是旧实例,这样做的好处是避免了一些并发的问题,也符合reactive programming中流式的概念。如果连接已经断开,则进行连接清理的工作,其中最关键的是将permit归还,从而允许创建新连接。
其实到此为止,我们已经完全弄清楚了整个连接池的原理,其获取和回收机制。回到一开始的问题,为什么连接异常关闭的时候连接没有被正常归还从而造成连接泄漏呢?
我们再看下上文提到的hook机制,它在channel关闭的时候会调用poolRef.invalidate(), 这个函数和poolRef.release()并没有什么不同,可以看下它的实现:
public Mono<Void> invalidate() {
return Mono.defer(() -> {
if (markInvalidate()) {
//immediately clean up state
ACQUIRED.decrementAndGet(pool);
return pool.destroyPoolable(this).then(Mono.fromRunnable(pool::drain));
}
else {
return Mono.empty();
}
});
}
boolean markInvalidate() {
return STATE.compareAndSet(this, STATE_ACQUIRED, STATE_RELEASED);
}
函数先检查一下当前的状态是否是STATE_ACQUIRED,如果是的话,更新成STATE_ACQUIRED状态再进行连接清理,清理过程和release中提到的一样,最终都会调用pool.destroyPoolable()方法进行释放和清理。
这就非常诡异了,poolRef.invalidate()中的确是有清理操作,那为什么却没有清理成功呢?
梳理整个回收过程,唯一的可能就是markInvalidate这个函数返回了False,也就是说PoolRef的状态并不是预期的STATE_ACQUIRED,而是另外两种状态,STATE_IDLE或者STATE_RELEASED。
STATE_IDLE状态可以排除。因为poolRef在从Connections Queue中获取的时候是会标记成STATE_ACQUIRED才开始进行http请求的。STATE_RELEASED状态更加不可解释。这个状态说明PoolRef已经被释放过了,那连接就不会泄漏。
分析陷入了僵局…
只能修改reactor-netty的源码,用map存储了历史的所有PoolRef,查看出问题的PoolRef到底是什么状态,用ide打断点得到泄漏的PoolRef的信息如下:
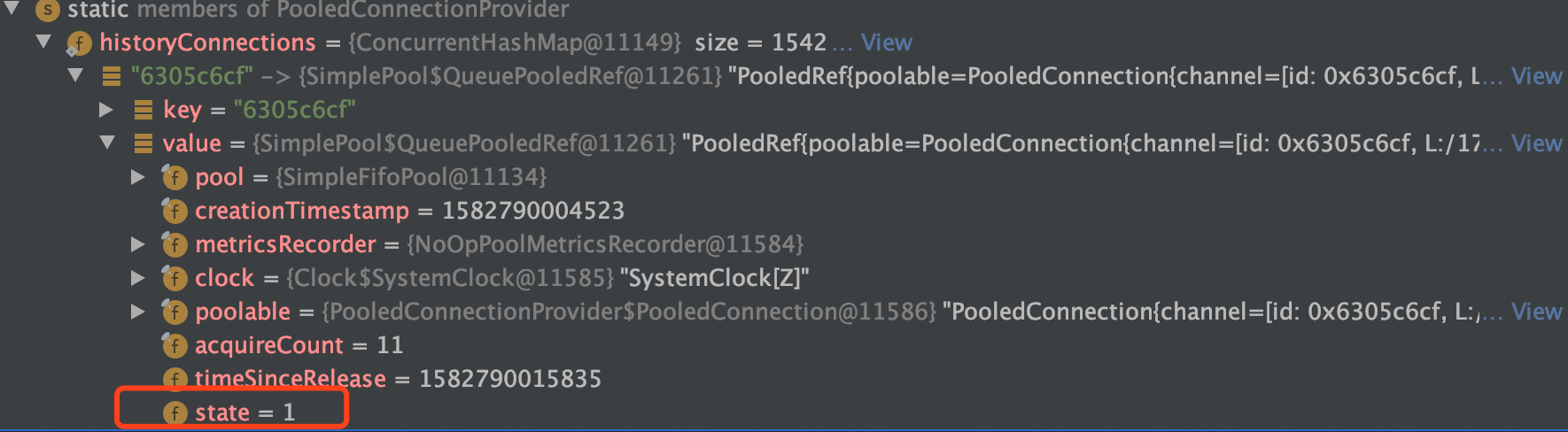
泄漏的PoolRef最终的state值居然是1,也就是STATE_ACQUIRED,让人完全大跌眼镜!如果是STATE_ACQUIRED的话,最终应该是要被清理掉然后更新成STATE_RELEASED。而map中其他正常被释放的PoolRef也的确都是STATE_RELEASED状态。说明这些处于STATE_ACQUIRED状态的PoolRef是没有被清理回收过的。
另外,我在poolRef.invalidate()调用前后获取其状态,并在回调中将状态信息打印了出来,结果如下:
Channel closed, now 150 active connections and 0 inactive connections, originState:2, invalidState:2
诡异的现象来了:PoolRef调用invalidate前后的值都是2,也就是STATE_RELEASED,打断点看的时候状态是1,日志打印的状态又是2,这难道是薛定谔的状态嘛!
分析再次陷入了僵局…
真相大白
这种现象其实还有一种合理解释,就是hook中的PoolRef和最终要被释放的PoolRef不是同一个。上面分析过,每次归还连接的时候是新构造一个PoolRef加入到空闲连接队列中,那意味着每次获取的PoolRef实例是不一样的,但其底层包装的channel其实是同一个。那么channel注册hook的时候,传递进去的PoolRef是哪一个呢?看代码:
PooledConnection pooledConnection = pooledRef.poolable();
Channel c = pooledConnection.channel;
// 设置channel的OWNER
ConnectionObserver current = c.attr(OWNER)
.getAndSet(this);
if (current instanceof PendingConnectionObserver) {
// TODO: 似乎不会走到这条路径,有待研究?
PendingConnectionObserver pending = (PendingConnectionObserver)current;
PendingConnectionObserver.Pending p;
current = null;
registerClose(pooledRef, pool);
while((p = pending.pendingQueue.poll()) != null) {
if (p.error != null) {
onUncaughtException(p.connection, p.error);
}
else if (p.state != null) {
onStateChange(p.connection, p.state);
}
}
}
}
// 首次进行hook注册
else if (current == null) {
registerClose(pooledRef, pool);
}
从上面代码可以知道,channel在第一次被aquire之后会设置OWNER,后面不会在进行hook的注册,所以hook中的PoolRef是第一次对chanenel包装的实例。而这个PoolRef如果经过了正常的http请求响应,是会被正常调用poolRef.release()进行连接释放的。所以就会出现上面日志中hook前后都显示STATE_RELEASED状态。而最后一次遇到连接中断问题的PoolRef却没有真正被释放,从而导致了连接泄漏的现象。
修复
知道了根本原因,修复就比较简单了,在原issue上贴了我的分析,作者也非常效率了提了一个PR,改动如下:
void registerClose(PooledRef<PooledConnection> pooledRef, InstrumentedPool<PooledConnection> pool) {
Channel channel = pooledRef.poolable().channel;
if (log.isDebugEnabled()) {
log.debug(format(channel, "Registering pool release on close event for channel"));
}
channel.closeFuture()
.addListener(ff ->
((DisposableAcquire) channel.attr(OWNER).get()).pooledRef
.invalidate()
.subscribe(null, null, () -> {
if (log.isDebugEnabled()) {
log.debug(format(channel, "Channel closed, now {} active connections and " +
"{} inactive connections"),
pool.metrics().acquiredSize(),
pool.metrics().idleSize());
}
}));
}
改动很小,就是从channel中的OWNER属性中取出最新的PoolRef进行invalidate操作,清理并归还连接至连接池中。
至此,升级项目中reactor-netty版本至最新的SNAPSHOT版本,本文一开始的问题就得到解决,大功告成!
总结
- 善用github issue, 有前人之鉴,可以减少很多分析时间
- 日志分析、源码分析有针对性,自顶向下逐步缩小区域、定位问题,否则如大海捞针
- 善用IDE的DEBUG工具,可以复现现场、定位问题