使用Reactor进行反应式编程
反应式编程是什么?
维基百科中对其的一句话定义如下:
Reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change.
首先反应式编程是一种声明式的编程范式。声明式意味着更关注结果的描述性,而不是具体的执行过程。比如SQL就是最常见的声明式语言,其他代表性的还有逻辑编程语言Prolog和函数式编程语言Lisp等。反应式编程其实属于函数式编程的一种,将计算表示成函数,可以通过高阶函数将各种函数进行组合,提供了极大的扩展性,同时也拥有了函数式编程带来的优点,比如延迟计算和更简单的并发抽象。
其次,反应式编程关心的是数据流,即一系列随时间推移而出现的离散事件。这篇简单易懂的介绍将其描述如下:
Reactive programming is programming with asynchronous data streams.
所有的输入都可以看做数据流,反应式编程是对这些数据流进行异步处理。如果说面向对象编程中一切都是对象,那么反应式编程中一切都是数据流。通过数据流和函数模型,是对并发和并行的更高层次的抽象,可以降低编写并发和并行程序的复杂度。
最后,反应式编程中反应的另一层意思是变化传播,整个系统可以快速检测到问题并作出即时的响应,动态调整资源以适应变化的系统负载。
反应式编程历史
Rx.NET作者Erik Meijer在给《RxJava反应式编程》一书的序中说到:
我们要专注于发明一种简单的编程模型,用于构建大规模异步和数据密集型的互联网服务架构。
因此,在2009年,时任微软架构师的Erik开发了Rx.Net。2012年开源并制定了Reactive Extension(也被称之为ReactiveX),可以将Rx移植到其他语言中。
同年,从微软跳槽到Netflix的Jafar Husain说服了当时负责Netflix API的Ben Christensen采用Rx编程,并因此开发了RxJava并开源。正是这一举动使得Rx在Java世界中大放异彩。有意思的是,这三位大佬现在都在Facebook工作。
特别的,虽然RxJava最初是用做Netflix后端API项目中,但是其在前端Android开发中也得到了广泛使用,基于数据流的反应式编程非常适合客户端各种事件响应以及复杂的网络交互的场景。
2015年,Spring团队决定基于Reactive Stream API和Java8重新开发一个JVM上的反应式编程库,称为Reactor,主要解决后端微服务场景下各种复杂的异步网络交互,并将其集成到了Srping 5中,这一举措更是助推了反应式编程在后端领域的流行。
为什么要进行反应式编程?
反应式宣言中给出了反应式系统的整个架构如下:

上图体现了反应式系统的价值,可以让系统即时响应(responsive),可维护(mantainable)和可扩展(extensiable)。系统表现形式是具有回弹性(Resilient)和弹性(Elastic):
- 回弹性(Resilient)是指系统在出现失败时依然要保持即时响应性。关注的是失败恢复。
- 弹性(Elastic)是指系统在不断变化的工作负载之下依然保持即时响应性。关注的是资源利用率。
构建反应式系统的方式是基于消息驱动,通过异步的消息传递,确保了松耦合、隔离、位置透明的组件之间有着明确边界。针对异步编程和消息驱动,传统的命令式编程需要定义复杂的状态交互解决并发问题,而反应式编程通过数据流和函数式编程,提供了更好的并发和并行的抽象,使得编写基于消息驱动的程序更加简单。构建反应式系统并不一定需要反应式编程,但是反应式编程可以让我们轻松构建反应式系统,
具体的说,反应式编程可以有如下优势:
- 可读性,声明式的描述方式更加直观,避免陷入Callback Hell,这也是为什么反应式编程采用了函数式风格而不是命令式的回调风格。
- 高层次并发抽象,使得异步编程更加简单。
- 可复用、松耦合的组件,提供各种高阶函数。
- 回压(backpressure),提供失败恢复策略,使得系统可以具有回弹性(Resilient)和弹性(Elastic)。
如何进行反应式编程?
有很多反应式编程库帮助开发者可以快速进行反应式编程,比如RxJava、Reactor。
David Karnok作为RxJava项目的leader,给出了Reactive库的代际发展:
-
第0代,JDK中的
java.util.ObservableAPI和基于callback(addXXXListener)API。这些API是典型的观察者模式,很难使用且不可组合。 -
第1代,以微软提出的Rx.NET库为代表,设计的
IObservable/IObserverAPI,但是其整个设计是同步的,而且没有回压处理。 -
第2代,以RxJava 1.x和Akka为代表,实现了Reactive Extensions规范,也称之为ReactiveX,可以实现非阻塞的应用,并且实现了回压处理。
-
第3代,以RxJava 2.x和Reactor为代表,实现了Reactive Streams API,Reactive Streams提出了一致的反应式编程接口,使得各个实现了反应式库可以互相兼容,允许用户可以替换底层实现。Reactive Streams API已经成为JDK9的规范。
-
第4代,以RxJava 2.x和Reactor 3.0为代表,仍然沿用Reactive Streams API接口,但内部构建了通用的算子(operator)集合以及性能优化。
-
第5代,未来版本,计划支持双向reactive IO。
Reactive Streams API
Reactive Streams API提供了反应式编程的最小接口集合,我们可以先review下这些API,对理解反应式编程理念有很大帮助。
- Publisher,发布者,可以发布无限序列的消息,可以根据订阅者的需求push消息,在任意时间点都可以动态服务多个订阅者,其接口如下:
public interface Publisher<T> {
/**
* 请求发布者开始发布消息
* 可以被多次调用,每次调用相互独立,会新建一个Subscription(发布订阅上下文)
* 每个Subscription只服务一个Subscriber
* 一个Subscriber只能subscribe一个Publisher
* 如果Publisher拒绝此次订阅或者订阅失败会触发onError回调
*/
public void subscribe(Subscriber<? super T> s);
}
- Subscriber,订阅者,消费发布者发布的消息,可以进行订阅、消费消息、接收完成、接收错误等动作,其接口如下:
public interface Subscriber<T> {
/**
* 当调用Publisher.subcribe(Subscriber)时会被触发
* Subscriber负责进行Subscription.request(long)调用,只有这个调用发生时才会开始真正的数据流
* Publisher只会响应Subscription.request(long)操作
*/
public void onSubscribe(Subscription s);
/**
* Publisher在接收到Subscription.request(long)调用时,通知订阅者进行消费
*/
public void onNext(T t);
/**
* 失败终止状态通知
*/
public void onError(Throwable t);
/**
* 成功终止状态通知
*/
public void onComplete();
}
- Subscription,表示一个订阅者订阅发布者的上下文,用于控制数据交换,可以请求或者取消数据交换,其接口如下:
public interface Subscription {
/**
* 只有当此方法被调用时,发布者才会发布消息
* 发布者只可以发布小于等于请求的数据量以保证安全性
*/
public void request(long n);
/**
* 通知发布者停止发布数据并清理相关资源
* 发布者不会立即停止发布数据,会等到上一次请求的数据量发布完成后结束
*/
public void cancel();
}
- Processor,表示发布者和订阅者之间数据处理的阶段,可以看成是发布者和订阅者之间的管道,其接口如下:
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
Reactor是什么?
Reactor是Spring团队基于Reactive Streams API实现的第4代反应式编程库。相比RxJava,Reactor没有厚重的历史包袱,其全新的实现使得其概念更加清晰和易于使用。
Reactor支持JVM平台上完全的非阻塞反应式编程以及高效的回压处理,分别提出了Flux和Mono两种反应式的可组合的API来对数据流建模。
另外,Reactor团队还提供了Reactor-Netty的反应式网络库,可以快速实现具有回压机制的网络应用程序。
Spring 5.0的WebFlux也采用Reactor库实现反应式系统。
如何用Reactor进行反应式编程?
Reactor实现了Reactive Streams API,下面介绍下Reactor中的关键特性。
Mono和Flux
Mono和Flux是Reactor中的两个基本组件。Flux表示0或N个元素的异步序列,Mono表示0或1个元素的异步序列。
虽然Flux也可以表示0或1个元素的异步序列,但是Mono明确表示了序列的基数,使得语义更加清晰,比如一次Http请求只有一个响应,这种情况下用Mono<HttpResponse>表示比Flux<HttpResponse>更加合理。
Flux数据流处理示意图如下所示:
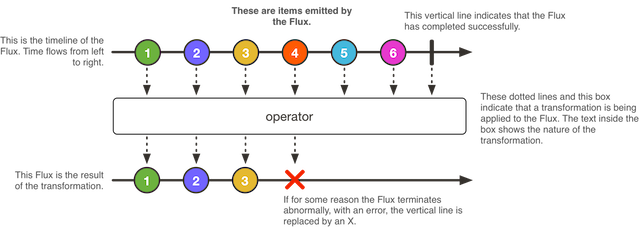
operator是一系列应用在Flux数据流中的每一个元素上的算子,会生产出新的数据流。Flux除了发布数据流外,还会发布错误事件和成功完成事件标志整个流的结束。
相对应的,Mono数据流处理示意图如下所示:
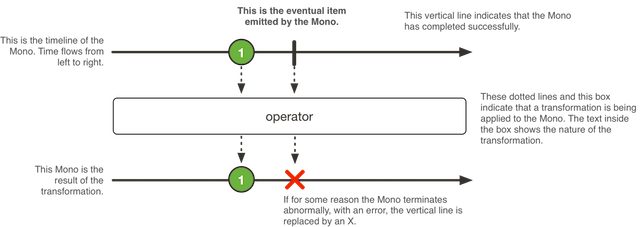
Backpressure回压
回压是反应式编程中的核心概念。回压是指发布者的生产速率大于订阅者的消费速率时,下游对上游的压力反馈。反应式宣言中,对回压一词的描述如下:
当某个组件正竭力维持响应能力时, 系统作为一个整体就需要以合理的方式作出反应。 对于正遭受压力的组件来说, 无论是灾难性地失败, 还是不受控地丢弃消息, 都是不可接受的。 既然它既不能(成功地)应对(压力), 又不能(直接地)失败, 那么它就应该向其上游组件传达其正在遭受压力的事实, 并让它们(该组件的上游组件)降低负载。 这种回压(back-pressure)是一种重要的反馈机制, 使得系统得以优雅地响应负载, 而不是在负载下崩溃。 回压可以一路扩散到(系统的)用户, 在这时即时响应性可能会有所降低, 但是这种机制将确保系统在负载之下具有回弹性 , 并将提供信息,从而允许系统本身通过利用其他资源来帮助分发负载,参见弹性。
其核心是订阅者需要一种机制主动告知发布者自己的需求,从Subscription的接口也可以看出,通过Subscription.request告知Publisher需求量以避免Publisher生产过快从而导致buffer溢出。回压机制的引入将push模式变成push-pull模式。
Reactor中的大多数操作符都已经内置了回压的功能,所以基本上用户在编写代码时基本上不需要再操心回压的事情,
Reactor中的回压机制的一个例子如下:
public static void log(Object o) {
System.out.println(
"[" + Thread.currentThread().getName()
+ "]\t| "
+ o);
}
@Test
public void testBackPressure() throws Exception{
CountDownLatch latch = new CountDownLatch(1);
Flux.interval(Duration.ofMillis(100))
.publishOn(Schedulers.parallel(), 1)
.subscribe(new BaseSubscriber<Long>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
log("onSubscribe");
request(1);
}
@Override
protected void hookOnNext(Long value) {
log("onNext:" + value);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
request(1);
}
@Override
protected void hookOnError(Throwable throwable) {
throwable.printStackTrace();
latch.countDown();
}
@Override
protected void hookOnComplete() {
latch.countDown();
}
});
latch.await();
}
我们用 Flux.interval(Duration.ofMillis(100))以每100ms的速率生产一个Long值,并在BaseSubscriber.hookOnNext中执行Thread.sleep(1000)以每1秒的速率消费一个Long值。
需要注意的是为了防止消费和生产在同一线程中,调用了publishOn来指定消费线程池,并指定prefetch为1,表示1秒只请求一个值。这样做的原因是因为interval操作符默认会使用内部的Schedule线程执行定时生产,如果消费和生产的在同一线程之中,就直接会阻塞生产,达不到我们想要的效果。
显而易见,此时消费速率跟不上生产速率。这种情况下,interval下会抛出异常,上面代码的输出日志如下:
[Test worker] | onSubscribe
[parallel-1] | onNext:0
reactor.core.Exceptions$OverflowException: Could not emit tick 1 due to lack of requests (interval doesn't support small downstream requests that replenish slower than the ticks)
at reactor.core.Exceptions.failWithOverflow(Exceptions.java:234)
at reactor.core.publisher.FluxInterval$IntervalRunnable.run(FluxInterval.java:130)
at reactor.core.scheduler.PeriodicWorkerTask.call(PeriodicWorkerTask.java:59)
at reactor.core.scheduler.PeriodicWorkerTask.run(PeriodicWorkerTask.java:73)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
从上面日志可以看到,只消费了0之后就抛出异常了。那这种情况下要如何处理呢?可能如下几种选择:
- 提高消费能力
- 降低生产速率
- 只消费部分数据,有若干选择策略,比如丢弃、忽略、抛异常、取最新数据
实际情况下,1和2都很难改变,为了让系统可以正常运行,只能选择3来保证部分可用(正如反应式宣言中的Resilient)。比如我们将上面的例子改成如下:
Flux.interval(Duration.ofMillis(100))
.onBackpressureDrop(drop -> log("drop:" + drop))
.publishOn(Schedulers.parallel(), 1)
.subcribe(...)
添加onBackpressureDrop策略,丢弃多余的数据,可以使整个程序仍然可用。此时部分输出日志如下:
[Test worker] | onSubscribe
[parallel-1] | onNext:0
[parallel-2] | drop:1
[parallel-2] | drop:2
[parallel-2] | drop:3
[parallel-2] | drop:4
[parallel-2] | drop:5
[parallel-2] | drop:6
[parallel-2] | drop:7
[parallel-2] | drop:8
[parallel-2] | drop:9
[parallel-2] | drop:10
[parallel-1] | onNext:11
从上面输出日志可以看到,Flux.interval仍然按照既定速率生产数字0~11,但是消费者只消费了数字0和数字11,其他数字都被丢弃了。
Scheduler反应式线程模型
默认情况下,Reactor是并发无关的,意思是作用在Flux和Mono上的操作符执行的线程是延用调用链上前一个操作符所执行的线程。所以,没有任何处理的情况下,同一个流的所有操作都是在subscribe调用线程上执行的。这样的好处是用户在subscribe的时候不需要考虑并发的问题,将并发的决策权交给用户。
Reactor提供了两种方法来设置执行的上下文:PublishOn和SubscribeOn。
PublishOn是用来指定后续算子执行所在线程,具有以下性质:
- 只影响
PublishOn调用之后的算子 - 切换执行上下文到指定的
Scheduler - 影响
Subscriber.onNext方法执行所在线程。比如上面例子中,sleep是在PublishOn中指定的线程中执行的 - 除非调用链后面有额外指定
PublishOn,否则沿用前面的Scheduler
SubscribeOn是用来指定整个调用链上下文的执行线程,具有以下性质:
- 影响整个调用链,调用链中最早出现的
SubscribeOn作为最终的线程配置 - 不影响之后出现的
PublishOn配置
下面举一个例子说明以上原则:
@Test
public void testScheduler() throws Exception{
CountDownLatch count = new CountDownLatch(1);
Scheduler s1 = Schedulers.newParallel("scheduler-A", 4);
Scheduler s2 = Schedulers.newParallel("scheduler-B", 4);
Flux.range(1, 2)
.map(i -> { log("mapA:" + i); return i; })
.subscribeOn(s1)
.map(i -> { log("mapB:" + i); return i; })
.publishOn(s2)
.map(i -> { log("mapC:" + i); return i; })
.subscribe(i->log("subscribe:" +i),
t -> count.countDown(),
count::countDown);
count.await();
}
上面用了3个map输出当前执行线程,mapA和mapB之间调用subcribeOn指定执行线程池为scheduler-A,而在mapB和mapC之间调用publishOn指定线程池为scheduler-B。我们可以看到以下输出结果:
[scheduler-A-2] | mapA:1
[scheduler-A-2] | mapB:1
[scheduler-A-2] | mapA:2
[scheduler-A-2] | mapB:2
[scheduler-B-1] | mapC:1
[scheduler-B-1] | subscribe:1
[scheduler-B-1] | mapC:2
[scheduler-B-1] | subscribe:2
从上述日志可以发现,Flux.range以及mapA和mapB都是在scheduler-A-2线程中执行的,说明subscribeOn的确会影响调用链上的所有算子,而和其位置无关。
但是mapC和subscribe是在scheduler-B-1中执行的,说明publishOn只会影响其后续的算子,而不会影响其前置的算子。
另外,我们注意到虽然通过SubscribeOn和PublishOn指定了操作符的线程池,但Flux流中所有元素都是由操作符选择的同一个线程进行处理的。正如之前所说,同一个流中的所有元素默认是在同一个线程中执行的,除非指定了Scheduler。
那Reactor中怎样才可以使流中的元素并发执行呢?答案就是flatMap,这个操作符相当于转换成另一个流,我们可以在新的流中指定Scheduler,这样就可以保证元素并发处理了。如下例所示:
public Mono<String> addPrefix(int val) {
return Mono.just("prefix_" + val)
.doOnNext(s -> log("addPrefix:" + s));
}
@Test
public void testFlatMap() throws Exception {
CountDownLatch count = new CountDownLatch(1);
Flux.range(1, 3)
.flatMap(i -> addPrefix(i)
.subscribeOn(Schedulers.parallel()))
.subscribe(
s -> log("main:" + s),
t -> count.countDown(),
count::countDown);
count.await();
}
假设我们有一个addPrefix函数为每个数字添加一个前缀,方法返回一个Mono表示延迟执行这个计算,这里只是举例用,实际情况下addPrefix可能是一个耗时操作。接下来,通过Flux.range生成3个整型值,并在flatMap中调用addPrefix,指定新流所在的Scheduler。我们可以看到如下输出:
[parallel-2] | addPrefix:prefix_2
[parallel-3] | addPrefix:prefix_3
[parallel-1] | addPrefix:prefix_1
[parallel-2] | main:prefix_2
[parallel-3] | main:prefix_1
[parallel-3] | main:prefix_3
此时addPrefix已经在多个线程中分别执行了,特别注意的是,main中的subscribe所在线程沿用了addPrefix所在线程。
总结
反应式编程的提出主要是为了解决异步编程的复杂性,是一种对并发和并行的更高抽象(通过数据流和函数式),让开发者从传统命令式编程复杂状态交互逻辑中解放出来。
对于习惯了命令式编程的我们来说,一开始学习函数式编程或者反应式编程来说可能有陡峭的学习曲线,主要原因还是束缚于命令式的惯性思维,需要一定时间的思维转化。
实际上,反应式编程编写出来的程序更加优雅、直观(相对于用命令式编程进行并发编程来说),值得我们尝试用反应式编程解决工作中遇到的问题。