为什么Kafka需要Leader Epoch?
为什么Kafka需要Leader Epoch?Leader Epoch是在KIP-101[1]里提出用来解决数据不一致的问题。
虽然网上也有很多资料来讲解这个问题,但是有很多关键点没有点明,看完之后还是会有很多疑问。本文试图以KIP-101为准,尽量解释清楚这个问题的前因后果。如有错误,还请指正。
回答这个问题之前,需要先大致了解下Kafka的副本策略ISRs,以及高水位(High Watermark,HW)的概念。
副本策略(ISRs)
Kafka的副本策略称为ISRs(in-sync replicas),动态维护了一个包含所有已提交日志的节点集合,通过zookeeper存储该集合,并由zookeeper从集合中选出一个节点作为leader,日志会先写入到leader,再由ISRs中的其他follower节点主动进行复制同步。
关于为什么Kafka没有采用类似Raft、Paxos的Quorum算法,官方文档也做了说明:
对于大吞吐日志系统而言,用Quorum太浪费。如果要容忍f个节点失败,Quorum需要2 * f + 1个节点,而ISRs只需要f+1个。
我们知道Quorum算法是为了解决脑裂问题,而ISRs这里不会出现这个问题的原因是zookeeper本身是一个分布式协调服务,可以通过zookeeper保证leader的唯一性。
kafka副本策略另外一个设计是每次日志写入并不会进行fsync等刷盘操作,刷盘会导致两到三倍的性能损失。崩溃的节点恢复后并不一定拥有完整的数据,但是可以通过和leader重新同步来加入ISRs。这个设计是产生我们原始问题的一个原因,下面会详细分析。
高水位(High Watermark)
高水位(High Watermark,HW)并不是什么高深的概念,其实和Raft中的commitIndex异曲同工,表示已经提交(commit)的最大日志偏移量。Kafka中某条日志“已提交”的意思是ISRs中所有节点都包含了此条日志。
对于ack设置为all的producer的一条写请求,leader会等到ISRs中的所有follower都拉取到此条日志后才会更新自己的HW,同时回复给producer写成功。这里有一个很微妙的点在于,不同于一般的leader通知follower进行日志写入的模式,kafka中是由follower主动拉取leader的日志进行同步的。
那follower什么时候更新自己的HW呢?答案是等待follower下次拉取leader日志的时候,leader告诉follower当前HW是多少,follower才会更新自己的HW。这里HW的延迟更新是产生我们原始问题的另一个原因。
这个类似于两阶段提交的模式其实很常见,比如在raft中,leader拿到多数节点的回复后并不会立马把结果再告知follower,而是等到客户端下次请求或是心跳的时候顺带将commit信息告知follower,这样leader只需要一轮交互就可以返回给客户端写成功。
另外,再多介绍下Kafka节点日志中的另一个偏移量Last End Offset,简称为LEO,表示节点本地日志最新的偏移量的下一个位置。
问题分析
KIP-101中列举了两个场景,描述了在没有提出leader epoch的情况下,会出现两种数据不一致的问题。下面逐一分析这两个场景。
场景一:日志丢失问题
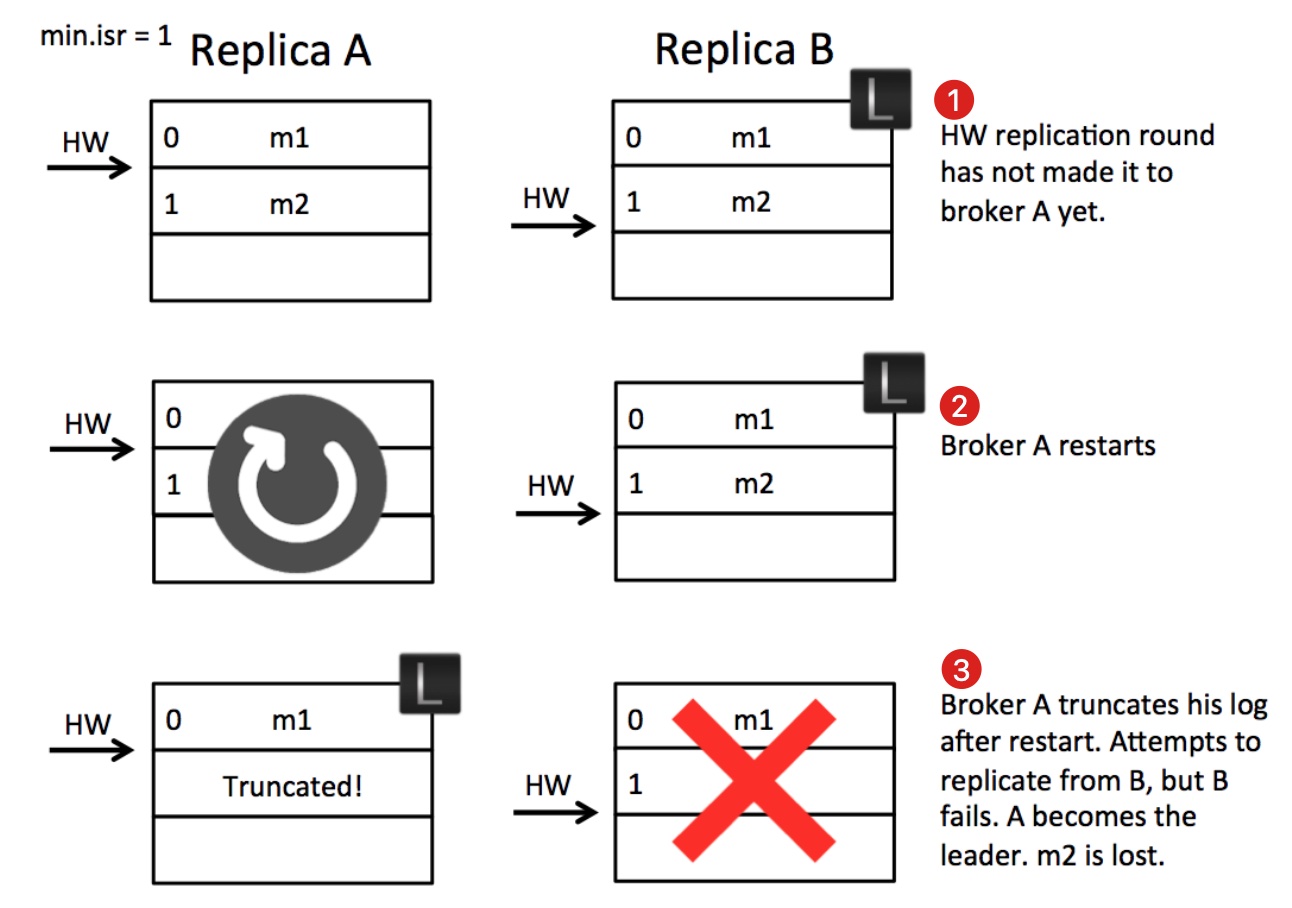
首先是考虑第1步中的状态可能发生吗?是可能的:
- 副本B作为leader收到producer的m2消息并写入本地文件,等待副本A拉取。
- 副本A发起消息拉取请求,请求中携带自己的最新的日志offset(LEO=1),B收到后更新自己的HW为1,并将HW=1的信息以及消息m2返回给A。
- A收到拉取结果后更新本地的HW为1,并将m2写入本地文件。发起新一轮拉取请求(LEO=2),B收到A拉取请求后更新自己的HW为2,没有新数据只将HW=2的信息返回给A,并且回复给producer写入成功。此处的状态就是图中第一步的状态。
此时,如果没有异常,A会收到B的回复,得知目前的HW为2,然后更新自身的HW为2。但在第2步A重启了,没有来得及收到B的回复,此时B仍然是leader。A重启之后会以HW为标准截断自己的日志,因为A作为follower不知道多出的日志是否是被提交过的,防止数据不一致从而截断多余的数据并尝试从leader那里重新同步
第3步,B崩溃了,min.isr设置的是1,所以zookeeper会从ISRs中再选择一个作为leader,也就是A,但是A的数据不是完整的,从而出现了数据丢失现象。
问题在哪里?在于A重启之后以HW为标准截断了多余的日志。不截断行不行?不行,因为这个日志可能没被提交过(也就是没有被ISRs中的所有节点写入过),如果保留会导致日志错乱。根本原因KIP-101也提到了:
So the essence of this problem is the follower takes an extra round of RPC to update its high watermark.
原因是follower需要额外一次RPC请求才能得到leader的HW。所以不能直接根据自身的HW截断日志。
场景二:日志错乱问题
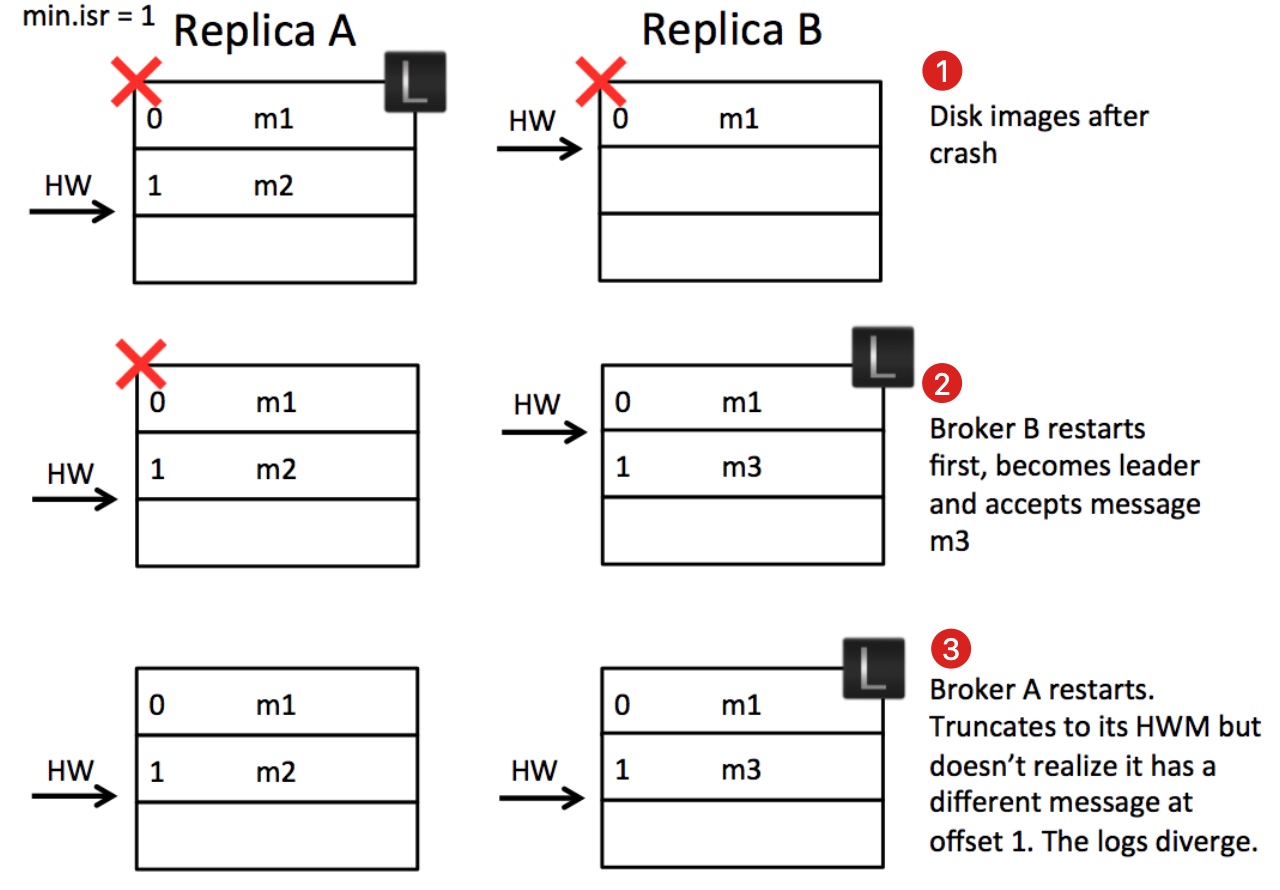
在分析日志错乱的问题之前,我们需要了解到kafka的副本可靠性保证有一个前提:在ISRs中至少有一个节点。如果节点均宕机的情况下,是不保证可靠性的,在这种情况会出现数据丢失,数据丢失是可接受的。这里我们分析的问题比数据丢失更加槽糕,会引发日志错乱甚至导致整个系统异常,而这是不可接受的。
首先考虑第1步中的状态可能发生吗?是可能的:
- A和B均为ISRs中的节点。副本A作为leader,收到producer的消息m2的请求后写入PageCache并在某个时刻刷新到本地磁盘。
- 副本B拉取到m2后写入PageCage后(尚未刷盘)再次去A中拉取新消息并告知A自己的LEO=2,A收到更新自己的HW为1并回复给producer成功。
- 此时A和B同时宕机,B的m2由于尚未刷盘,所以m2消息丢失。此时的状态就是第1步的状态。
第2步,由于A和B均宕机,而min.isr=1并且unclean.leader.election.enable=true(关闭unclean选择策略),所以Kafka会等到第一个ISRs中的节点恢复并选为leader,这里不幸的是B被选为leader,而且还接收到producer发来的新消息m3。注意,这里丢失m2消息是可接受的,毕竟所有节点都宕机了。
第3步,A恢复重启后发现自己是follower,而且HW为2,并没有多余的数据需要截断,所以开始和B进行新一轮的同步。但此时A和B均没有意识到,offset为1的消息不一致了。
问题在哪里?在于日志的写入是异步的,上面也提到Kafka的副本策略的一个设计是消息的持久化是异步的,这就会导致在场景二的情况下被选出的leader不一定包含所有数据,从而引发日志错乱的问题。
这里额外引出一个问题,ISRs中选出的leader一定是安全(包含所有已提交数据)的吗?是的,除非ISRs中的节点全部宕机,全部宕机的情况下会出现数据丢失。
Leader Epoch的引入
为了解决上面提出的两个场景存在的问题,我们可以分析下产生这两个场景的原因是否有什么共性。
场景一提到因为follower的HW更新有延时,所以错误的截断了已经提交了的日志。场景二提到因为异步刷盘的策略,全崩溃的情况下选出的leader并不一定包含所有已提交的日志,而follower还是以HW为准,错误的判断了自身日志的合法性。所以,不论是场景一还是场景二,根本原因是follower的HW是不可靠的。
其实,如果熟悉raft的话,应该已经发现上面分析的场景和raft中的日志恢复很类似,raft中的follower是可能和leader的日志不一致的,这个时候会以leader的日志为准进行日志恢复。而raft中的日志恢复很重要的一点是follower根据leader任期号进行日志比对,快速进行日志恢复,follower需要判断新旧leader的日志,以最新leader的数据为准。
这里的leader epoch和raft中的任期号的概念很类似,每次重新选择leader的时候,用一个严格单调递增的id来标志,可以让所有follower意识到leader的变化。而follower也不再以HW为准,每次奔溃重启后都需要去leader那边确认下当前leader的日志是从哪个offset开始的。
KIP-101引入如下概念:
- Leader Epoch: leader纪元,单调递增的int值,每条消息都需要存储所属哪个纪元。
- Leader Epoch Start Offset: 新leader的第一个日志偏移,同时也标志了旧leader的最后一个日志偏移。
- Leader Epoch Sequence File: Leader Epoch以及Leader Epoch Start Offset的变化记录,每个节点都需要存储。
- Leader Epoch Request: 由follower请求leader,得到请求纪元的最大的偏移量。如果请求的纪元就是当前leader的纪元的话,leader会返回自己的LEO,否则返回下一个纪元的Leader Epoch Start Offset。follow会用此请求返回的偏移量来截断日志。
我们再看下引入Leader Epoch之后是如何解决上面的两个场景的。
场景一:

这里的关键点在于副本A重启后作为follower,不是忙着以HW为准截断自己的日志,而是先发起LeaderEpochRequest询问副本B第0代的最新的偏移量是多少,副本B会返回自己的LEO为2给副本A,A此时就知道消息m2不能被截断,所以m2得到了保留。当A选为leader的时候就保留了所有已提交的日志,日志丢失的问题得到解决。
有人可能会有疑问,如果发起LeaderEpochRequest的时候就已经挂了怎么办?这种场景下,不会出现日志丢失,因为副本A被选为leader后不会截断自己的日志,日志截断只会发生在follower身上。
场景二:

这里的关键点还是在第3步,副本A重启作为follower的第一步还是需要发起LeaderEpochRequest询问leader当前第0代最新的偏移量是多少,由于副本B已经经过换代,所以会返回给A第1代的起始偏移(也就是1),A发现冲突后会截断自己偏移量为1的日志,并重新开始和leader同步。副本A和副本B的日志达到了一致,解决了日志错乱。
总结
通过以上分析,我们终于可以回答本文最开始提出的问题:
为什么Kafka需要Leader Epoch?
Kafka通过Leader Epoch来解决follower日志恢复过程中潜在的数据不一致问题。
另外,我们从分析中还可以有一些额外的收获,那就是如何保证kafka高可用?
- 关闭unclean策略,必须等到ISRs中的节点恢复
- 设置ISRs的最小大小,设置的越多越可靠(当然性能也会相应损失)
总之,由于极其复杂的交互和部分失败的存在,设计一个具有容错性、一致性、扩展性分布式系统是非常不容易的。