Netty数据结构之HashedWheelTimer
定时器(Timer)是程序开发的常用工具,可以创建各种定时任务,特别是在异步编程的场景下,会依赖定时任务触发各种事件。在有大量定时任务的场景下,Timer的执行性能会影响到整个系统的性能。
George Varghese和Tony Lauck提出了Hashed Timing Wheel的数据结构,将Timer的各种操作的时间复杂度降低到O(1),极大的提高了Timer的性能。
Netty也实现了Hashed Timing Wheel的思想,内部类名为HashedWheelTimer,在Netty3版本中的定时任务用到了此数据结构,比如空闲连接检测。虽然在Netty4中的定时任务不再采用HashedWheelTimer,参考issue[2],作者解释如下:
just because we usually want to be on the same thread as the EventLoop of the Channel. that said there is nothing wrong about the HashedWheelTimer.
只是想让定时任务在EventLoop中执行,原因可能是统一channel的相关操作的执行线程,与channel的数据读写保持一致,减少线程数和线程切换,并不意味着这个实现是有问题的。
下面分析下HashedWheelTimer的实现。
现有的Timer为什么不满足要求?
在分析Hashed Timing Wheel之前,先看下为什么现有的数据结构不满足要求?
George Varghese和Tony Lauck的论文中提到Timer有三种操作:
- START_TIMER,启动一个定时任务
- STOP_TIMER,关闭一个定时任务
- PER_TICK_BOOKKEEPING,每次tick时钟后执行最早的定时任务
可以通过分析上述三种操作的复杂度来对比各个数据结构。其中STOP_TIMER一般都是O(1)的时间复杂度,因为我们可以直接引用到某个具体的Timer并进行关闭。所以下面我们更加关注的是START_TIMER和PER_TICK_BOOKKEEPING。
首先最直接的是单个未排序链表,每次新增Timer直接追加到末尾,所以这种情况下START_TIMER是O(1)的时间复杂度,但是PER_TICK_BOOKKEEPING每次需要遍历一遍链表找到最早应该执行的任务,所以PER_TICK_BOOKKEEPING的时间复杂度为O(n)。
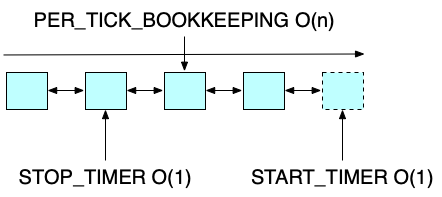
然后是排序的链表,由于链表是根据Timer超时时间排序的,START_TIMER需要遍历链表找到插入位置,所以START_TIMER的时间复杂度为O(n),相反的,PER_TICK_BOOKKEEPING则只需要取队首元素即可,时间复杂度为O(1)。
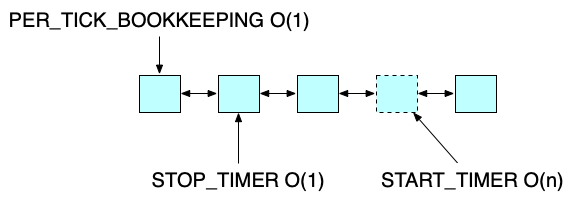
最后是最常用的堆,java中的PriorityQueue或者ScheduledThreadPoolExecutor的DelayedWorkQueue,都是用的堆。堆的特性使得START_TIMER的时间复杂度变为O(log(n)),此时PER_TICK_BOOKKEEPING则只需要取堆顶元素即可,时间复杂度为O(1)。
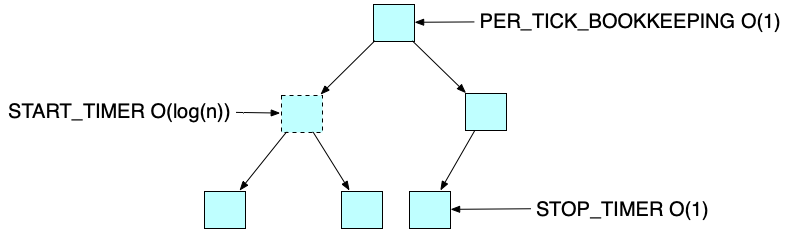
O(log(n))的时间复杂度好像还是不尽人意,是否有O(1)的时间复杂度呢?哈希的数据结构就是可以O(1)时间进行查找和删除,把时钟tick作为key,比如1s、2s、3s等,value是待执行的定时任务,但如果时间上限很大的话,key组成的数组会非常大,非常耗内存。解决问题的办法是使用环形数组,环形数组长度为n的话,转一轮的时间为n * tick,tick是单次时钟长度,对于那些时间跨度超过一轮的任务,可以通过计算剩余轮数来标志任务是否需要执行。这就是Hashed Timing Wheel的思想:哈希 + 时间轮。如下图所示:
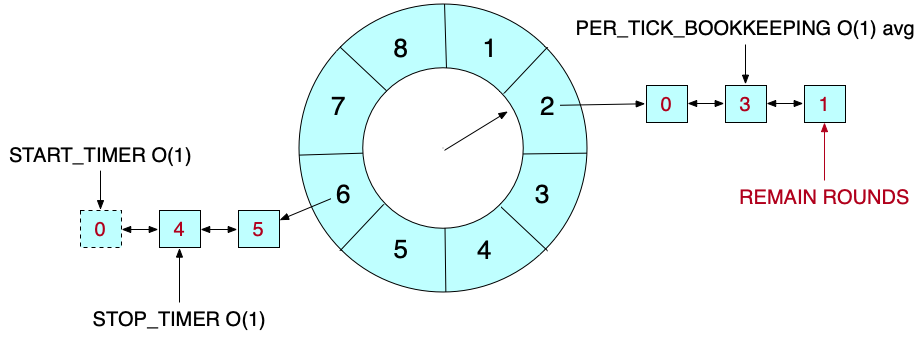
这样,START_TIMER和PER_TICK_BOOKKEEPING的平均时间复杂度就是O(1)了,为什么说是平均呢?因为最坏情况下,所有的任务都会在一个bucket内,这个时候START_TIMER和PER_TICK_BOOKKEEPING就有一个的时间复杂度退化成O(n)。具体是哪一个,取决于开放链表是否是排序的,如果开放链表有序,则START_TIMER为O(n);如果开放链表无序,则PER_TICK_BOOKKEEPING为O(n)。当然,如果时间轮越精细,则时间复杂度越小,消耗空间也越大。
Netty的HashedWheelTimer解析
初始化的参数
先看下初始化接口:
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
......
// Normalize ticksPerWheel to power of two and initialize the wheel.
wheel = createWheel(ticksPerWheel);
mask = wheel.length - 1;
// Convert tickDuration to nanos.
long duration = unit.toNanos(tickDuration);
......
workerThread = threadFactory.newThread(worker);
......
}
private static HashedWheelBucket[] createWheel(int ticksPerWheel) {
......
ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);
HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];
for (int i = 0; i < wheel.length; i ++) {
wheel[i] = new HashedWheelBucket();
}
return wheel;
}
关键的两个参数:
- tickDuration,表示单次tick持续时间是多久,决定了最小时间单位。
- ticksPerWheel,表示时间轮上的bucket数目。
这两个参数决定了时间轮转一轮的时间跨度,即为tickDuration * ticksPerWheel。
另外maxPendingTimeouts表示最大持有的任务数,防止占用内存太多。然后就是创建时间轮数组,对数组长度进行正则化,好通过mask快速进行mod计算。workerThread就是进行时间推进的线程,每次停顿tickDuration的时间进行任务的处理。
添加定时任务
接下来,看下添加一个定时任务的接口:
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
......
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
......
// 启动后台线程,定时轮转
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
......
// HashedWheelTimeout包装了定时任务,是一个双向链表的节点
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
// private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue();
timeouts.add(timeout);
return timeout;
}
这里HashedWheelTimeout就是封装了真实的定时任务的对象,作为bucket的双向链表中的节点,并附带了剩余轮数信息。另外注意到,添加定时任务并没有直接添加到时间轮中,还是先放到一个timeouts队列中,等workerThread下次调度的时候才会放入到时间轮中,timeouts队列是用JCTools生产的无锁CAS队列。
HashedWheelBucket和HashedWheelTimeout
HashedWheelBucket是时间轮数组中的元素,是一个双向链表结构。HashedWheelTimeout是双向链表中的节点,封装了真实任务的HashedWheelTimeout:
private static final class HashedWheelTimeout implements Timeout {
// 任务状态
private static final int ST_INIT = 0;
private static final int ST_CANCELLED = 1;
private static final int ST_EXPIRED = 2;
// netty中常见的性能优化,原子性的任务更新,不直接采用AtomicInteger,而是用AtomicIntegerFieldUpdater+volatile
// 可以减少内存占用,后者比前者节省16字节,见http://normanmaurer.me/blog/2013/10/28/Lesser-known-concurrent-classes-Part-1/
private static final AtomicIntegerFieldUpdater<HashedWheelTimeout> STATE_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(HashedWheelTimeout.class, "state");
private final HashedWheelTimer timer;
private final TimerTask task;
private final long deadline;
@SuppressWarnings({"unused", "FieldMayBeFinal", "RedundantFieldInitialization" })
private volatile int state = ST_INIT;
// remainingRounds will be calculated and set by Worker.transferTimeoutsToBuckets() before the
// HashedWheelTimeout will be added to the correct HashedWheelBucket.
long remainingRounds;
// This will be used to chain timeouts in HashedWheelTimerBucket via a double-linked-list.
// As only the workerThread will act on it there is no need for synchronization / volatile.
HashedWheelTimeout next;
HashedWheelTimeout prev;
// The bucket to which the timeout was added
HashedWheelBucket bucket;
......
}
关键参数:
- state: 任务状态, 包括初始化、取消、过期。
- remainingRounds: 剩余轮转数
- deadline: 过期时间
- task: 原始任务
- next,prev: 双向链表指针
- bucket: 所属bucket
- timer: 所属timer
Worker
接下来,就是最关键的时间推进线程,执行过程如下:
@Override
public void run() {
// Initialize the startTime.
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
// Notify the other threads waiting for the initialization at start().
startTimeInitialized.countDown();
do {
// 等待下一次时间调度
final long deadline = waitForNextTick();
if (deadline > 0) {
// tick存了当前第几次时钟。找到当前tick所属的bucket。
int idx = (int) (tick & mask);
// 处理被取消的任务,取消的任务会被放进cancelledTimeouts队列
processCancelledTasks();
// 拿到对应bucket
HashedWheelBucket bucket =
wheel[idx];
// 将timeouts队列中待执行的任务放进时间轮中
transferTimeoutsToBuckets();
// 执行清理该bucket中过期的任务
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
// Fill the unprocessedTimeouts so we can return them from stop() method.
for (HashedWheelBucket bucket: wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (;;) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}
流程非常清晰:
- 等待并计算下一次调度时间
- 清理被取消的任务
- 将队列中的任务放进时间轮中
- 查找当前bucket,执行并根据下一次调度时间清理bucket中的任务
我们看下第3和第4步的过程,首先是将timeouts队列中待处理的任务放进时间轮的transferTimeoutsToBuckets函数:
private void transferTimeoutsToBuckets() {
// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
// adds new timeouts in a loop.
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
long calculated = timeout.deadline / tickDuration;
timeout.remainingRounds = (calculated - tick) / wheel.length;
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
// 直接插入尾结点
bucket.addTimeout(timeout);
}
}
单次调度最多取100000个任务,防止待执行的任务饥饿。这里就是根据任务的deadline计算属于哪一个bucket以及剩余轮数(remainingRounds),并将其放进对应的bucket中。
然后再看下bucket.expireTimeouts(deadline)函数:
/**
* Expire all {@link HashedWheelTimeout}s for the given {@code deadline}.
*/
public void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
// 如果剩余轮数<=0,表示需要进行执行,并将其移除
next = remove(timeout);
if (timeout.deadline <= deadline) {
// 合法的deadline,只能延后执行,不能提前执行
// expire中会直接运行任务
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
// 被取消的也移除
next = remove(timeout);
} else {
// 减少轮次
timeout.remainingRounds --;
}
timeout = next;
}
}
expireTimeouts主要负责遍历一遍bucket双向链表中所有任务,执行或移除相关任务,对于剩余轮数大于0的任务,需要减少其轮次。
总结
本文分析了HashedWheelTimer的思想及其在netty中的实现,主要在于两点:
- 哈希的数据结构,决定了时间复杂度是O(1)。
- 时间轮,可以通过控制单次tick的时钟以及轮盘的bucket数来控制精度,引入剩余轮次(remain rounds)的概念, 可以减少内存占用。
其实,原论文还提出了多级时间轮的概念, 采用多个时间轮,每个时间轮的精度不一样,类似于秒、分、时的概念。Kakfa内部实现的定时任务就是多级时间轮,在此不作展开。