Kafka和RocketMQ文件存储机制对比
Kafka和RocketMQ作为高性能的分布式消息系统,两者高性能的核心都在于基于OS文件系统的持久化设计。Kafka在其官方文档中提到:
Don’t fear the filesystem!
不要害怕文件系统!我们需要打破对磁盘I/O性能低下的固有印象。现代OS对文件系统的优化可以让磁盘I/O读写速度堪比内存读写,其中的奥秘就是大名鼎鼎的PageCache。
PageCache是什么?
PageCache是一种针对磁盘I/O的优化机制,系统内核通过页管理机制将磁盘内容缓存在一部分内存之中,以提供更快的磁盘读写。
也就是说,我们平常写文件时,并不是直接和磁盘打交道,而是写入PageCache后就直接返回,同样地,读文件时也可以先从PageCache中读取,没有找到时才从磁盘中读取。通过在磁盘和用户态添加一层PageCache,可以弥补高性能的CPU和低性能的磁盘读写之间的鸿沟。
系统内核线程会定期将PageCache中的脏页进行刷盘(flush)保持磁盘内容和PageCache的一致性。机器断电的情况下,数据可靠性如何保证?一种是可以每次写入时手动刷盘,另一种是通过副本机制保证数据可靠性。
由于是OS自己维护PageCache,所以只要OS不崩溃,即使应用程序异常退出,OS仍然可以将PageCache中的数据进行刷盘。这种特性带来一个好处是:当应用程序崩溃重启时,热点数据仍然在PageCache中,对应用性能的影响可以达到最小。
另外,针对JVM语言构建的系统,使用PageCache可以减少GC带来的损耗,而且不用自己维护cache,可以简化代码设计。
Kafka和RocketMQ都使用了文件系统,并利用了PageCache带来的特性。Linux也提供了多种文件I/O机制,比如pwrite,mmap,Direct I/O等。下面先简单介绍下Linux的I/O机制,然后再分别介绍Kafka和RocketMQ的文件存储设计并对两者做一个比较。
Java文件I/O实现
这篇博客较为全面的介绍了Linux各种I/O机制的原理。这里不再细讲,着重介绍各个机制在Java中的实现。
FileChannel
FileChannel是java.nio包中对操作系统文件I/O系统调用的封装。
FileChannel.write和FileChannel.read相当于Linux的pwrite和pread系统调用,通过ByteBuffer将用户态数据精确写入到PageCache中。如果文件是顺序读写,会达到和访问内存一样的效果。另外这两个方法都是线程安全的,内部通过锁机制进行并发控制。
/**
* Writes a sequence of bytes to this channel from the given buffer,
* starting at the given file position.
*/
public abstract int write(ByteBuffer src, long position) throws IOException;
/**
* Reads a sequence of bytes from this channel into the given buffer,
* starting at the given file position.
*/
public abstract int read(ByteBuffer dst, long position) throws IOException;
FileChannel.transferTo相当于Linux的sendfile系统调用,sendfile的效果就是传说中的零拷贝,避免用户态和核心态的数据拷贝,配合DMA,可以实现将文件中的数据直接从核心态复制到网卡,从而实现高效的数据传输。但这个弊端是不能对文件中的数据进行额外的处理。 ```java /**- Transfers bytes from this channel’s file to the given writable byte
- channel. *
- This method is potentially much more efficient than a simple loop
- that reads from this channel and writes to the target channel. Many
- operating systems can transfer bytes directly from the filesystem cache
- to the target channel without actually copying them. * */ public abstract long transferTo(long position, long count, WritableByteChannel target) ```
MappedByteBuffer
MappedByteBuffer相当于Linux的mmap内存映射机制。
内存映射文件(Memory-mapped file),或称“文件映射”、“映射文件”,是一段虚内存逐字节对应于一个文件或类文件的资源,使得应用程序处理映射部分如同访问主内存。
也就是说应用程序可以直接以指针的方式操作核心态的内存(同样也是PageCache),操作系统会将脏页同步到磁盘上。相对于普通的write和read,可以省去用户态到核心态之间的数据拷贝,大幅度提高I/O效率。
mmap的另外一个使用场景是,需要随机访问大文件中的小部分数据,并且大概率会再次访问附近的数据,这种场景下缺页中断概率很小,使用mmap可以得到很大的性能提升。
当然,并不是所有场景都适合使用mmap,Quora上有一个回答给出如下三种场景更适合用普通的write和read,而不是用mmap:
-
针对单一文件有很多个读写进程时,此时用mmap访问,进行同步的代价很大
-
如果访问的数据不在PageCache中,会导致缺页中断(page fault),其代价很高。所以如果只是顺序读写,用write/read更加适合,因为用户态到核心态的数据拷贝的代价比缺页中断的代价小的多
-
mmap启动和销毁有额外的开销,只有长时间需要将文件映射到内存中时才使用mmap
Direct I/O
Direct I/O,顾名思义,就是应用程序直接操作文件系统,不需要OS进行缓存,降低了对文件读写时的CPU和内存消耗。在某些应用场景下,比如数据库管理系统,传输大量数据时可以提高性能。目前JDK官方尚未支持DIO。
kafka存储机制
Kafka在设计之初就决定其底层数据结构采用队列的形式进行存储,这种方式比一般用B树存储的优势在于其可以充分利用磁盘顺序读写高性能的特性。
这种将性能和数据大小解耦的数据结构可以保证所有的读写操作的时间复杂度控制在O(1)之内,而且存储可以使用廉价的大容量SATA磁盘,这样消息持久化存储的时间更长,可以支持消费回溯等高级特性。
Kafka中队列的概念模型称之为patition,一个topic可以对应多个patition队列。每个patition逻辑上是一个大文件,但实际存储时会切割为大小均等的segment文件,并以最后一条消息在整个队列中的offset为当前segment的文件名,消息数据都是顺序追加到最新的segment文件中去。正常情况下,消息的生产和消费都是基于最新的segment进行读写,这样就可以命中PageCache达到非常高的性能。
另外,消费者是根据队列的offset进行消费的,虽然segment文件存储了具体的消息数据,但是每个消息大小是不一样的,所以为了定位消息在文件中的偏移量,需要为每一个segment文件额外再建立一个index文件用来进行队列offset到文件偏移量的索引,index文件名和segment文件名一致。具体地,比如想要查找队列offset为666666的消息,首先通过二分查找找到对应的index文件,index文件中通过稀疏索引记录了666666左右的消息在segment中的偏移量,然后再在segment中根据文件偏移量顺序查找到666666的消息。更详细的内容,可以查看Kafka文件存储机制那些事。
Kafka通过哪些I/O机制来访问index和segment文件呢?可以分为写和读两块:
写(生产)消息:
- index文件较小,可以直接用mmap进行内存映射
- segment文件较大,可以采用普通的write(FileChannel.write),由于是顺序写PageCache,可以达到很高的性能
读(消费)消息:
- index文件仍然通过mmap读,缺页中断的可能性较小
- segment可以使用sendfile进行零拷贝的发送给消费者,达到非常高的性能
RocketMQ存储机制
RocketMQ的存储机制借鉴了Kafka的设计,其出发点是为了单个topic在单台机器上可以分配更多的partition。
为什么这么说呢?这取决于消费端的负载均衡机制,ConsumerGroup中的消费者会均匀分配其订阅tipic的partition,而一个partition只能被一个消费者进行消费,所以如果partition的数量小于消费者的数量,那么多余的partition将得不到消费。所以如果想横向扩展消费者,必须增加partition的数量。
RocketMQ官方文档关于Kafka不能支持更多队列,给出如下解释:
- Each partition stores the whole message data. Although each partition is orderly written to the disk, as number of concurrently writing partitions increases, writing become random in the perspective of operating system.
- Due to the scattered data files, it is difficult to use the Linux IO Group Commit mechanism.
在Kafka文件读写中,针对segment文件写入是采用顺序write的,但是如果parition数量一多,从操作系统的角度看就变成了随机写入,导致写入性能下降。
RocketMQ给出如下解决方案:
-
所有的消息数据(不同topic、不同队列)都写入同一个文件(当然物理存储时还是会以固定大小进行文件切割),这个文件称之为CommitLog
-
为每个队列新增ConsumeQueue文件,存储消息在CommitLog中的文件偏移量
这样,ConsumeQueue变成了逻辑上的队列,但是不存储消息详情,类似于Kafka中的index文件。因为ConsumeQueue文件很小,所以创建很多个队列对性能没什么损失,所有消息详情都写入CommitLog使得该文件变成了完全的顺序写。
但这种方案会引入如下两个问题:
- commitLog为了保证顺序写入,需要进行加锁(RocketMQ默认使用单线程自旋锁),相对Kafka写入多个文件来说,同步成本更高
- commitLog一定程度上变成了随机读
我们再来看下RocketMQ使用的I/O机制:
写(生产)消息:
- 无论是ConsumeQueue还是CommitLog都使用mmap进行写
读(消费)消息:
- 无论是ConsumeQueue还是CommitLog都使用mmap进行读
ConsumeQueue文件且数据量也小,使用mmap读写性能更高,和Kafka读写index文件一致。那为什么CommitLog也采用了mmap,却没有像Kafka读写segment文件一样使用FileChannel呢?这是因为RocketMQ将所有队列的数据都写入了CommitLog,消费者批量消费时需要读出来进行应用层过滤,所以就不能利用到sendfile+DMA的零拷贝方式。
总结
通过以上介绍,我们可以绘制出如下表格,对比下Kafka和RocketMQ两者在存储机制上的差异:
| Kafka | RocketMQ | |
|---|---|---|
| 文件结构 | 1.index索引文件 2.多个队列多个segment消息文件 |
1.ConsumeQueue索引文件 2.多个队列一个CommitLog消息文件 |
| IO写 | 1.index文件采用mmap 2.segment采用write |
均采用mmap |
| IO读 | 1.index文件采用mmap 2.segment采用sendfile |
均采用mmap |
| 优点 | 1.每个topic的队列互不影响 2.数据量较大(>4kb)时写入性能更高 3.消费时可以利用sendfile+DMA零拷贝机制 |
1.commitLog完全顺序写 2.单机可以配置更多队列 |
| 缺点 | 1.单机队列配置较多时,有性能损失 | 1.随机读遇到缺页中断成本高 2.不能利用sendfile机制 |
针对单机配置队列数的benchmark,RocketMQ官方也给出了测试结果:
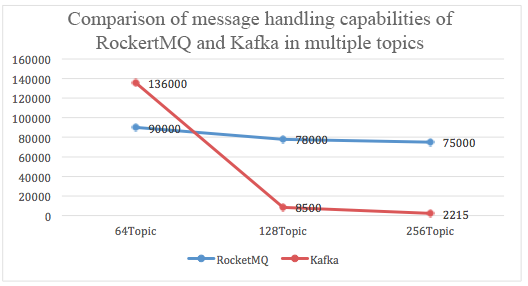
从上图可以看到,随着topic(队列)的增加,Kafka写入性能的确有损失(pagecache不够用了?内存足够的话会怎样呢?),如果真的需要单集群配置那么多的队列,似乎是偏向于用RocketMQ。
ps. 其实针对Kafka单机不能配置更多队列,部署更多的broker是否也可行呢?