分布式消息系统之多副本方案
分布式消息系统为了保证高可用性,需要实现多副本(Replication)方案,防止网络分区、节点宕机、程序GC停顿等造成的服务不可用。多副本,顾名思义,就是对消息存储的多份拷贝,其带来的副作用就是如何保持数据的一致性,是CAP理论所讨论的范围。
分布式消息系统,也可以称为发布订阅系统,是异步处理、模块解耦的重要组件,其关键概念有:
- topic,消息主题,一个topic可以有多个生产者和消费者
- partition(log),消息存储日志,也可称之为持久化队列,一个topic可能会有多个partition
- producer,消息生产者,将消息发布到指定的topic
- consumer,消息消费者,消费订阅的topic中的消息
这里的多副本的复制单元就是partition,要确保存储partition的节点宕机之后整个服务仍然可以正常工作。
RocketMQ和Kafka是目前常用的分布式消息系统的实现,也提供了各自不一样的多副本方案。本文以两者为例介绍下多副本的实现方案。
Master/Slave(主从模式)
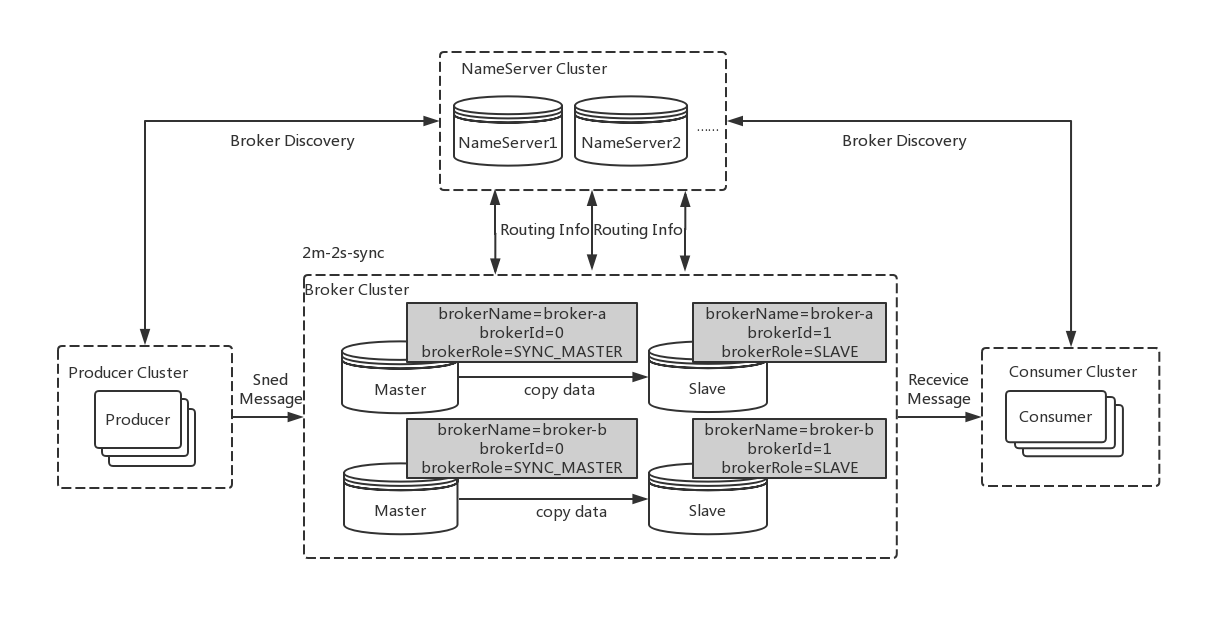
Master/Slave(主从模式)方案是最直接也最简单的复制方案。数据复制方向从Master到Slave。Mater挂了之后可以切换Slave为服务节点。Mysql常用的集群方案就是主从模式。RocketMQ4.5版本之前也是采用此方案,如下图所示:
{kind=link}

上图中RocketMQ的broker采用的2m-2s(两个master分别对应两个slave),将master存储的日志复制到slave中。
优点是:
- 实现简单
缺点是:
- master和slave的切换过程需要额外的程序处理,处理时间可能较长,降低了服务的可用性。
- 正常情况下slave不对外提供服务,浪费机器资源
Paxos/Raft
Paxos/Raft,基于分布式一致性协议的复制方案,可以支持在部分节点故障的情况下自动恢复服务。
分布式消息系统中的partition相当于复制状态机中的复制日志,一致性的定义是不同节点上的日志的数目和顺序是一致的。
分布式一致性协议的核心思想是大多数原则(Quorum,法定人数),对于2n+1个节点,只有消息在已经写入n+1个节点后才认为这条消息是committed的,意味着最多可以忍受n个节点故障。
针对Raft协议,采用leader选举机制,保证数据流只从leader流向follower,读写操作都在leader上,简化了paxos的复制过程。
RocketMQ4.6版本之后实现了Raft协议,称之为DLedger,将broker原先的master/slave模式切换成raft模式,如下图所示:
{kind=link}
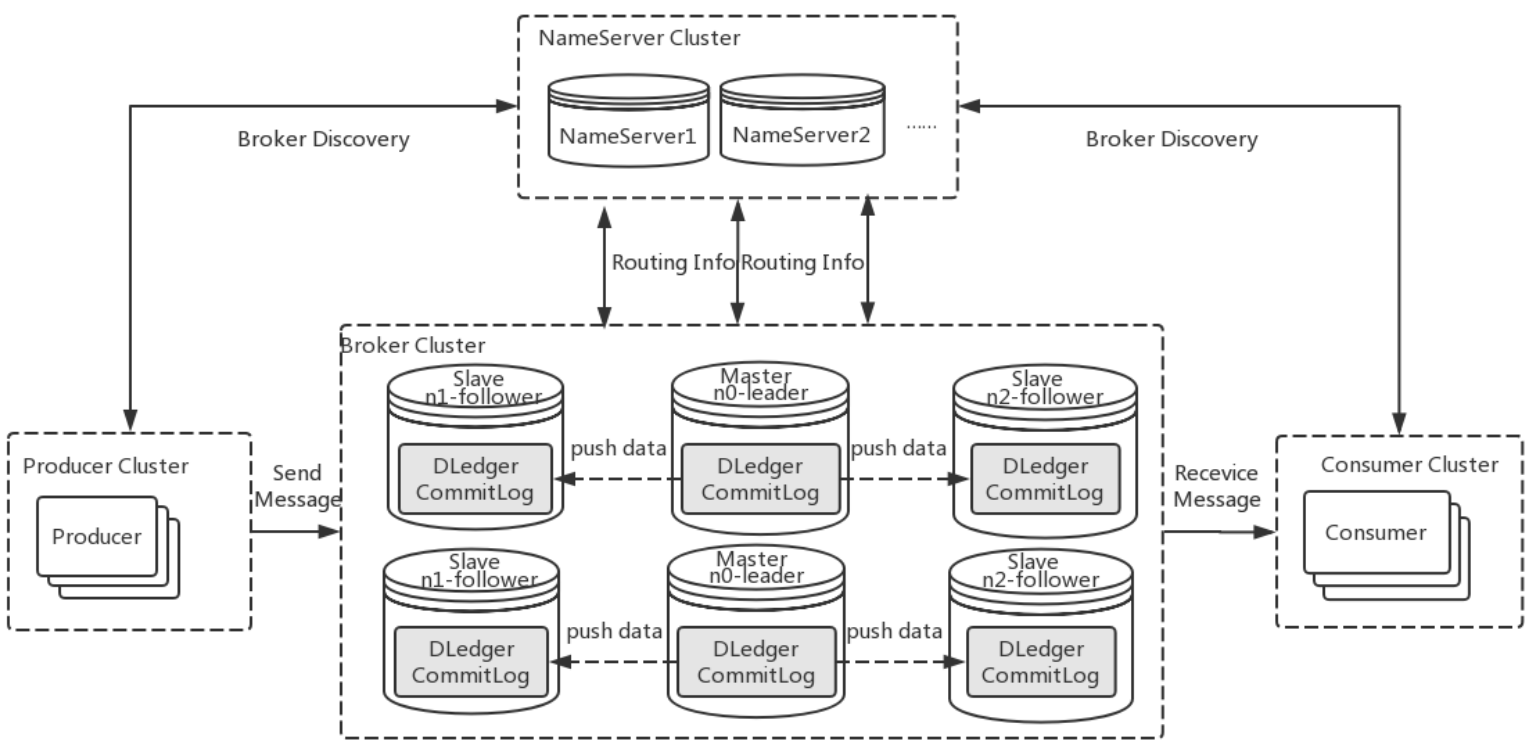
将原先的Master/Slave替换成3个节点,由于大多数原则,所以应用raft协议至少要3个节点,才可以忍受1个节点的故障,通过选主机制选出leader,日志复制从leader到follower。
优点是:
- 没有额外依赖
- 可以自动故障恢复
- 写入的延迟取决于最快的follower
缺点是:
- 实现复杂
- 如果要忍受n个节点故障,至少要部署2n+1个节点,浪费存储
ISRs
ISRs(In-Sync Replication Set)概念是Kafka提出并实现的一种的多副本策略。“In-Sync Replication Set”,从字面上理解是表示“在同步中的复制集合”。
和Raft一样,节点也分为leader和follower,leader会维护ISRs。其复制数据流如下图所示:
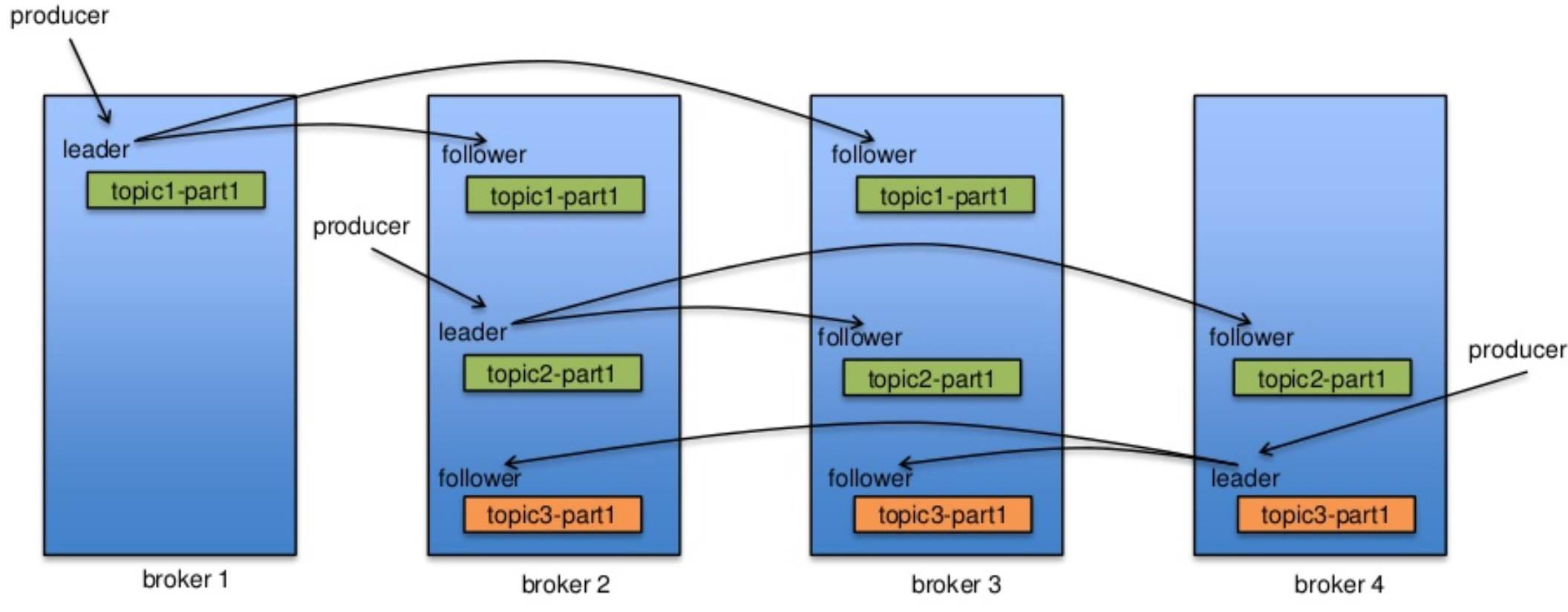
由上图可知,Kafka的副本分配策略和RocketMQ的raft副本策略不一样,RocketMQ中broker的角色要么是leader要么是follower,而Kafka的broker针对不同的patition可能既是leader也是follower。为了保证leader均匀分布,其副本分配策略如下:
- 将所有Broker(假设共n个Broker)和待分配的Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
一个follower是in-sync的,需要满足如下两个条件:
- 保持和ZooKeeper的会话
- follower需要及时从leader复制日志,不能落后太多
这边“不能落后太多“的意思是follower可能来不及响应、宕机等原因,没有及时从leader中复制日志。如果不满足上面的两个条件,则会被leader认为不是in-sync的,会将有问题的follower移出ISRs。
一条消息可以被认为是committed(已提交),当且仅当ISRs中的followers都已经将消息写到自己的日志中。消息在没有committed之前,对consumers是不可见的。只有committed的消息,才可以被consumers消费。
consumer不需要关心数据一致性,producer可以在一致性和可用性之前进行取舍。producer有三种ack机制:
- 0,表示不等leader写入本地日志就直接返回,纯异步的写入可以达到最大的吞吐量,但可靠性也最低,容易会丢数据
- 1,需要等待leader写入本地日志才返回,leader正常的情况下不会丢数据,但如果leader宕机,可能会丢数据
- -1,需要等到leader和ISRs中的follower都写入日志才返回,这种有最高的可靠性,不会丢数据,但相应的,吞吐量也会大大降低
leader是如何选择的?
ISRs的数据维护是交给ZooKeeper管理的,意味着ISRs的数据一致性可以交给ZooKeeper负责。
如果leader宕机了,那么显而易见,可以从ISRs中选择一个follower作为新的leader,因为当producer设置ack=-1时,ISRs中的follwer和leader必然是保持一致的。
从ISRs中选择的一个leader可以通过ZooKeeper的分布式锁机制实现,并保证只有一个节点可以选择成功。
如何处理ISRs中的节点都宕机的情形?
在ISRs中至少有一个follower时,Kafka可以保证committed的数据不丢失,但如果ISRs中的所有节点都宕机了,就无法保证数据不丢失。这种情况下有两种的选择:
-
等待ISRs中的任一个副本节点活过来,并且选它作为leader
-
选择第一个活过来的副本节点(不一定是ISRs中的)作为leader
第一种选择会影响可用性,如果ISRs中的节点恢复的慢的话,整个partition对外都是不可用的。如果对一致性进行妥协,可以选择第二种unclean的方案,至少可以提高可用性。
如何确保数据是可靠的?
这里需要先区分副本数(replication factor)和ISRs数,副本数是指每个partition需要多少个副本,而ISRs数指定了producer需要多少个ack。由上面讨论可知,需要满足以下条件:
- 关闭unclean的leader选举策略,意味着只有等待ISRs中的节点恢复。
- 设置最小的ISRs数,并且producer需要设置ack=all,表示需要等到ISRs中的所有节点写入日志才认为消息是committed
为什么不用Quorum机制?
正如上面提到的基于raft复制的缺点之一是,如果要忍受n个节点故障,至少要部署2n+1个节点,这对于大吞吐量的日志系统而言无疑是非常浪费资源的。所以quorum算法更多的是用在数据量较少的配置同步的系统中,比如ZooKeeper,或者HDFS的namenode模块。而对于ISRs方案来说,如果要忍受n个节点故障,则只要部署n+1个节点即可。ISRs可以达到这种效果的原因在于ISRs的数据一致性是交给ZooKeeper维护的,broker本身的数据复制就不需要满足Quorum原则。
但这也带来一个负面影响,消息写入成功的延迟取决于ISRs中最慢的节点,而不是像Raft那样只取决于最快的节点。
总结下ISRs副本策略优缺点,优点是:
- 节省存储资源,增大系统吞吐量。如果要忍受n个节点故障,则只要部署n+1个节点即可。
缺点:
- 依赖ZooKeeper
- 写入的延迟取决于最慢的follower
总结
每个副本策略各有其优缺点,需要根据实际场景选择方案。对于高吞吐量的日志系统而言,Kakfa的ISRs副本策略似乎更加合理。