Paxos如何直觉性推导?
分布式系统会面临三个问题:一致性(Consistence)、可用性(Availability)、分区容忍性(Network Partitioning)。CAP定理指出这三者不能全部满足,最多只能满足其中的2项。如何在这三者之间进行平衡是设计分布式系统的核心。Paxos是由Leslie Lamport提出的一种分布式共识(Consensus)算法,主要是保证数据的强一致性,并且在系统中大多数节点(过半)都正常的情况下,系统可以正常工作。所以Paxos是满足了一致性和分区容忍性,牺牲了一定的可用性。Paxos基本上是公认的分布式共识算法,很多工业界的系统(Chubby)和后续演变的共识算法(Raft和ZAB)都是基于Paxos的。但是,很多人吐槽Paxos原始论文晦涩难懂,因此Paxos作者发表了一篇全部采用英文大白话的算法论述叫Paxos made simple,循序渐进的描述了Paxos的推导过程。本文主要总结记录论文中是如何直觉性的推导出Paxos。
CAP定理
在介绍算法之前还是先介绍一下CAP定理
- 一致性(Consistence),指每次读请求返回的都是最新的数据副本
- 可用性(Availability),指每次请求都有一个非错的返回,但不保证是最新的数据
- 分区容忍性(Network Partitioning),指节点异常时系统仍然可以对外正常提供服务
一致性和可用性比较好理解,关键是『分区容忍性』的定义让人捉摸不透,其实在分布式系统中,节点和节点之间的通信不一定是可靠的,即通信消息是可重复、可延迟、可丢失的,(不考虑拜占庭问题,即消息可篡改)。当节点与系统中的其他节点通信有问题时,这时就是产生了网络分区。所以分区容忍性意味着,即使消息不可靠产生了网络分区,系统仍然可以正常对外提供服务。举一个例子是数据分布在系统的各个节点上,如果一个节点异常了,这个节点上的数据就不可访问了,这就表示分区不可忍。如果要满足分区可容忍,那么数据需要复制多份,这就带来了数据一致性的问题,要保证数据一致,往往又会降低系统的可用性(比如数据同步期间,系统对外不可访问)。所以说对于一个分布式系统,分区容忍性是必须符合的,接下来才有一致性和可用性之间的取舍。
Paxos
Paxos算法中给系统中的节点定义了3种角色:proposer(提议者)、accpetor(接受者)、leaner(学习者)。proposer和acceptor是协调一致的角色,leaner发现已经达成共识的值,本文只讨论达成共识的过程。一个节点可以担任一个或多个角色。在给出Paxos推导前,先祭出其终极形态,包括两个阶段:prepare阶段和accept阶段,两种请求:prepare请求,accept请求,这两种请求又可以称之为proposal(提议),每个提议都有一个唯一的proposal-number(提议号)标志以及value(需要达成一致的数据值)。
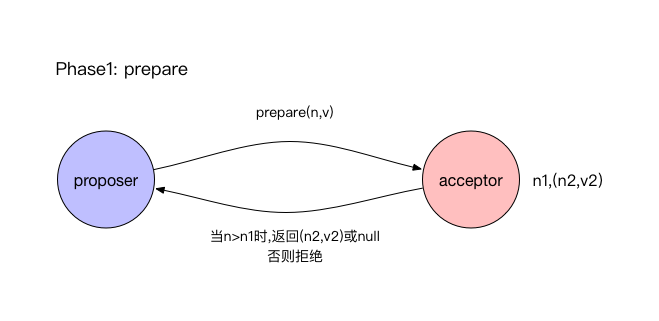
阶段1(prepare):
- proposer向大多数acceptor发送提议号为n的prepare请求。
- 如果acceptor收到新的prepare请求的提议号大于之前所有已回复过的prepare请求的提议号,则对prepare请求进行回复。回复表示向propser承诺不会再接受比n小的提议,回复时附带之前在accept阶段已经accpet过的拥有最大提议号的proposal,没有则不附带。
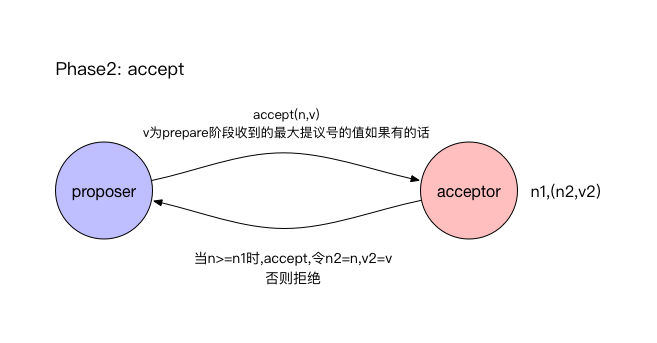
阶段2(accept):
- 如果proposer收到大多数accpetor对于prepare请求的回复,则发起提议号为n的accept请求。请求中的value等于prepare阶段收到的所有acceptor回复的拥有最大提议号的proposal的value,如果回复中没有proposal,则等于prepare阶段发起的值。
- 如果acceptor收到提议号为n的accept请求,那么acceptor可以accept这个请求,除非之前回复过的prepare请求的提议号大于n。
要解决什么问题?
在节点可宕机、可重启,消息可丢失、可重复、可延迟的前提下,系统中所有节点可以关于某个值达成共识。每个节点都可以提出某个值,共识算法是确保只有一个值是可以被选择,被确定的,所有的节点都对这个值达成了共识,对外表现出一致性。共识算法的安全性是指:
- 只有已被提出的值可以被选择
- 只有一个值可以被选择
- 一个节点不可以读取到未被选择的值除非值已经被选择
这边需要注意是当一个值被选择之后,达成共识之后就不可以再更改了。如果需要更改某个值可以通过复制状态机(Replicated State Machine)实现,共识过的历史记录都不可更改。
为什么要发送给大多数accptor?
首先,最简单的方案是单个acceptor,数据肯定能够达成一致,但很明显如果这个acceptor宕机,那么整个系统就不可用了。所以需要发送给多台acceptor,但是为什么是大多数?大多数是过半的意思,而两个大多数集合必然有一个交集,如果这个公共的acceptor至多接受一个值,一般情况下系统似乎是可以运行的。一个值被选择表示这个值被大多数acceptor接受。这边有一个隐含的要求,就是acceptor必须接受其收到的第一个提议,否则单个proposor的提议可能永远不会被接受。要求如下:
P1. 一个acceptor必须接受它收到的第一个提议
为什么要分两阶段?
如果按照上面的设计,acceptor只能最多接受一个提议,那么考虑下面这种场景,假设两个proposer的提议都被集群中的一半的acceptor接受,都没有被大多数accpetor接受,如果acceptor只能最多接受一个提议,那么这两个提议都会失败。
P1和大多数原则可以推导出acceptor必须可以接受多个提议。这里为了区分不同的提议,可以给每一个提议赋一个自增的唯一的提议号来标志时序。但是安全性要求只有一个值可以被选择(被大多数acceptor接受),所以满足以下要求可以满足安全性:
P2. 如果一个值为v的提议被选择,则所有被选择的更大提议号的提议的值都为v
『谁的提议号大,就接受谁的提议』这个方案为什么不可行呢?因为只要有拥有更大提议号的提议出来,且值不同,都可以被选择,这样就违反了安全性。如果要满足P2,可以满足下面要求:
P2a. 如果一个值为v的提议被选择,则所有被任何一个acceptor接受的更大提议号的提议的值都为v
意味所有被任何一个acceptor接受的更大提议号的提议的值都为v,则该提议肯定可以被选择且该提议值为v,满足P2。考虑如下场景,如果值为v1的提议已经被大多数acceptor接受,而c这个acceptor暂时没收到任何提议,此时v2的提议发送到c,根据P1要求,c必须接受这个提议,这样就违反了P2a。所以需要对P2a加强成如下要求:
P2b. 如果一个值为v的提议被选择,则所有的更大提议号的提议的值都为v
如果所有的更大提议号的提议的值都为v,那么被选择的提议的提议值当然也是为v,满足P2。为了满足P2b,直觉上是追溯历史信息,查看历史已经被选择的值,如果未来的提议也是这个值那么就满足了P2b的特性,所以可以追溯历史信息,从而提出如下要求:
P2c. 对于v和n,如果提议号为n,值为v的提议被提出,那么一个大多数acceptor集合S满足下面两个性质中的一个:(a)S中没有一个acceptor接受过提议号小于n的提议;(b)v是S中所有接受过提议号小于n的提议中提议号最大的提议值。
由数学归纳法可以证明满足P2c则满足P2bwiki证明。为了获取acceptor历史接受信息,需要多出一个阶段去询问acceptor,让acceptor告诉proposer其接受阶段接受的最大提议号的提议值。这个阶段称之为prepare阶段,有两个作用,一个是得到acceptor承诺,不会再接受小于提议号的提议,另一个是返回所有接受过提议号小于n的提议中提议号最大的提议。关于第一个作用,个人理解是锁定历史信息,让历史信息不再改变,否则acceptor能接受更小的提议号的话,数据就不一致了。所以P1还需要一个补充:
P1a. 一个acceptor可以接受提议号为n的提议当且仅当prepare阶段没有回复过提议号大于n的提议
对于P1a,acceptor不会接受比当前接受最大提议号小的提议,那么在prepare阶段也无需回复比当前最大提议号小的提议。另外,acceptor需要持久化prepare阶段和accept阶段接受的最大提议号的提议,以免acceptor宕机,重启之后仍然可以正常工作。
通过上述推导,可以得出本文一开始给出的Paxos两阶段提交算法,满足了P1,P1a和P2,进而满足了一致的安全性。
总结
Paxos首次给出了可容错的分布式系统下的一致性共识算法,两阶段提交的设计可以说是非常精致,省略任何一个步骤都会影响安全性。但是终究是理论上的描述,实现起来有非常多的细节考虑,Chubby的作者都指出来说虽然基于Paxos开发,但最后实现的一套其实已经不算是Paxos了。Raft也是基于Paxos演变的共识算法,其作者指出Paxos的可理解性太低,所以提出Raft定义了所有实现细节,包括选主、日志复制、成员变更、日志压缩等话题。后续会再出一个Raft的完整介绍,真正理解共识算法。
- 上一篇 分布式消息系统的若干问题
- 下一篇 易理解的raft共识算法